Интерактивно изучайте результаты Cleanlab на CIFAR-100 с помощью Renumics Spotlight

Очистка данных — важный, но часто недооцениваемый шаг в реальных проектах машинного обучения. Наличие неверных данных, в том числе неправильно помеченных примеров, выбросов и дубликатов, может существенно повлиять на производительность и надежность моделей машинного обучения. Для решения этих проблем появились инструменты очистки данных, такие как Cleanlab, которые стали ценными помощниками для автоматического обнаружения проблем с данными. Cleanlab использует уверенные методы обучения, реализуя подход модель в цикле.
Хотя инструменты очистки данных помогают выявлять потенциальные проблемы с данными, все же необходим тщательный анализ и изучение результатов, чтобы получить полное представление об основных проблемах.
Расширенные инструменты визуализации играют незаменимую роль в этом контексте. Такие инструменты, как Renumics Spotlight, не просто предоставляют передовые визуализации для выявления моделей сбоев; они также позволяют нам тщательно проверить проблемы с данными. Примером их возможностей является карта подобия, усовершенствованный интерактивный график уменьшения размерности, который использует встраивание модели для идентификации проблемных кластеров.
В этой статье мы сосредоточимся на концепции совместного использования Cleanlab и Spotlight для решения проблем с данными. В качестве примера набора данных мы используем популярный набор данных CIFAR-100.
Полный код также доступен в сопроводительной записной книжке на GitHub.
Отказ от ответственности. Автор этой статьи также является одним из разработчиков Spotlight.
Подготовка
Набор данных CIFAR-100 является эталонным набором данных в области компьютерного зрения для классификации изображений. Он состоит из 100 различных классов, сгруппированных в 20 суперклассов. Набор данных содержит 60 000 небольших цветных изображений размером 32x32 пикселя. Для нашего анализа мы сосредоточимся на 10 000 тестовых изображений и рассмотрим метку «отлично», которая представляет определенный класс каждого изображения.
Чтобы упростить наш анализ, мы будем использовать расширенную версию набора данных CIFAR-100, которая уже была дополнена вложениями, прогнозами и вероятностями. Этот набор данных был создан с использованием доработанной модели edumunozsala/vit_base-224-in21k-ft-cifar100 из Hugging Face model Hub.
Прежде чем мы начнем, мы устанавливаем необходимые библиотеки:
!pip install renumics-spotlight cleanlab datasets
Чтобы загрузить обогащенный набор данных CIFAR-100, мы можем использовать репозиторий Hugging Face library, импортировав модуль наборы данных и используя следующий код:
import datasets
ds = datasets.load_dataset("renumics/cifar100-enriched", split="test")
df = ds.to_pandas()
Набор данных будет иметь следующие столбцы:
- «изображение»: необработанные данные изображения.
- «fine_label»: метка ссылки, представленная в виде целого числа.
- «fine_label_str»: метка ссылки, представленная в виде удобочитаемой строки.
- «fine_label_prediction»: предсказанная моделью метка в виде целого числа.
- «fine_label_prediction_str»: предсказанная моделью метка в виде удобочитаемой строки.
- встраивание: вложения, сгенерированные из данных изображения с использованием модели Vision Transformer (ViT) [1], обученной на CIFAR-100: edumunozsala/vit_base-224-in21k-ft-cifar100.
- «вероятности»: значения вероятности, сгенерированные с использованием той же модели.
Автоматическое обнаружение проблем с данными с помощью Cleanlab
Теперь, когда у нас есть вероятности и готовые вложения в нашем фрейме данных df. Мы используем Cleanlab для выявления трех различных типов проблем в нашем наборе данных:
- Проблемы с метками: ошибки, связанные с неправильной или непоследовательной маркировкой.
- Выбросы: точки данных, которые значительно отклоняются от других наблюдений и могут снизить производительность модели.
- Почти дубликаты: почти идентичные точки данных, которые могут исказить результаты.
со следующим кодом:
import pandas as pd import numpy as np from cleanlab import Datalab lab = Datalab(data=df, label_name="fine_label") features = np.array([x.tolist() for x in df["embedding"]]) pred_probs = np.array([x.tolist() for x in df["probabilities"]]) lab.find_issues(features=features, pred_probs=pred_probs)
Метод find_issues позволяет нам анализировать вложения и предсказанные вероятности, в результате чего получается таблица проблем с данными. Эта таблица включает логические индикаторы для проблем с метками, выбросов и почти дубликатов, а также соответствующие оценки, отражающие достоверность каждого обнаружения:
lab.get_issues() +------+------------------+---------------+--------------------+-----------------+---------------------------+------------------------+ | | is_label_issue | label_score | is_outlier_issue | outlier_score | is_near_duplicate_issue | near_duplicate_score | |------+------------------+---------------+--------------------+-----------------+---------------------------+------------------------| | 0 | False | 0.152339 | False | 0.61018 | False | 0.432467 | | 1 | False | 0.967271 | False | 0.683433 | False | 0.268029 | | 2 | False | 0.981884 | False | 0.707834 | False | 0.299303 | | 3 | False | 0.989626 | False | 0.690585 | False | 0.313452 | | ... | ... | ... | ... | ... | ... | ... | | 9997 | False | 0.988529 | False | 0.707655 | False | 0.304715 | | 9998 | False | 0.990591 | False | 0.8521 | False | 0.111629 | | 9999 | False | 0.990379 | False | 0.634265 | False | 0.387416 | +------+------------------+---------------+--------------------+-----------------+---------------------------+------------------------+
Мы можем объединить эти обнаруженные проблемы с исходным фреймом данных df с помощью:
df = pd.concat([df, lab.get_issues()], axis=1)
Проверьте проблемы с данными с помощью Spotlight
После выявления потенциальных проблем с данными с помощью Cleanlab важно отметить, что только часть автоматически обнаруженных проблем являются реальными проблемами с данными (около 25% для CIFAR-100 [2]). Поэтому следующим важным шагом является рассмотрение и понимание этих вопросов. Spotlight предоставляет для этой цели комплексную интерактивную среду.
Ознакомьтесь с онлайн-демонстрацией этой статьи по адресу: huggingface.co/spaces/renumics/navigate-data-issues.
Сначала мы создаем DataIssues для представления проблем, обнаруженных Cleanlab:
from renumics.spotlight.analysis import DataIssue
label_issue_rows = df[df["is_label_issue"]].sort_values("label_score").index.tolist()
label_issue = DataIssue(
severity="medium",
title="label-issue",
rows=label_issue_rows,
description="Label issue found by Cleanlab - Review and correct if necessary",
)
outlier_issue_row = (
df[df["outlier_score"] < 0.6].sort_values("outlier_score").index.tolist()
)
outlier_issue = DataIssue(
severity="medium",
title="outlier-issue",
rows=outlier_issue_row,
description="Outlier score < 0.6 - Review and remove or collect more data",
)
near_duplicate_issue_row = (
df[df["is_near_duplicate_issue"]].sort_values("near_duplicate_score").index.tolist()
)
near_duplicate_issue = DataIssue(
severity="medium",
title="near-duplicate-issue",
rows=near_duplicate_issue_row,
description="Near duplicate issue found by Cleanlab - Review and remove if necessary",
)
Представления содержат список индексов всех примеров для каждой из трех проблем и отсортированы по соответствующей оценке проблемы. Эти представления вместе с DataFrame df передаются в Spotlight. Spotlight использует проблемы с данными, чтобы показать три группы проблем, что позволяет нам выбирать и отображать все примеры для группы, отсортированные по оценке проблемы.
from renumics import spotlight
dtypes = {
"image": spotlight.Image,
"full_image": spotlight.Image,
"embedding": spotlight.Embedding,
"embedding_reduced": spotlight.Embedding,
"probabilities": spotlight.Embedding,
}
spotlight.show(
df.rename(columns={"fine_label_str": "label", "fine_label_prediction_str": "pred"}),
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_data_issues.json",
issues=[label_issue, outlier_issue, near_duplicate_issue],
)
Кроме того, необработанные данные изображения из DataFrame df используются для отображения изображений, что делает возможным рассмотрение проблем данных с исходными данными. Кроме того, вложения используются для создания карты сходства с использованием UMAP (равномерная аппроксимация и проекция многообразия). Это позволяет нам перемещаться по изображениям и находить похожие изображения для выявленных проблем.
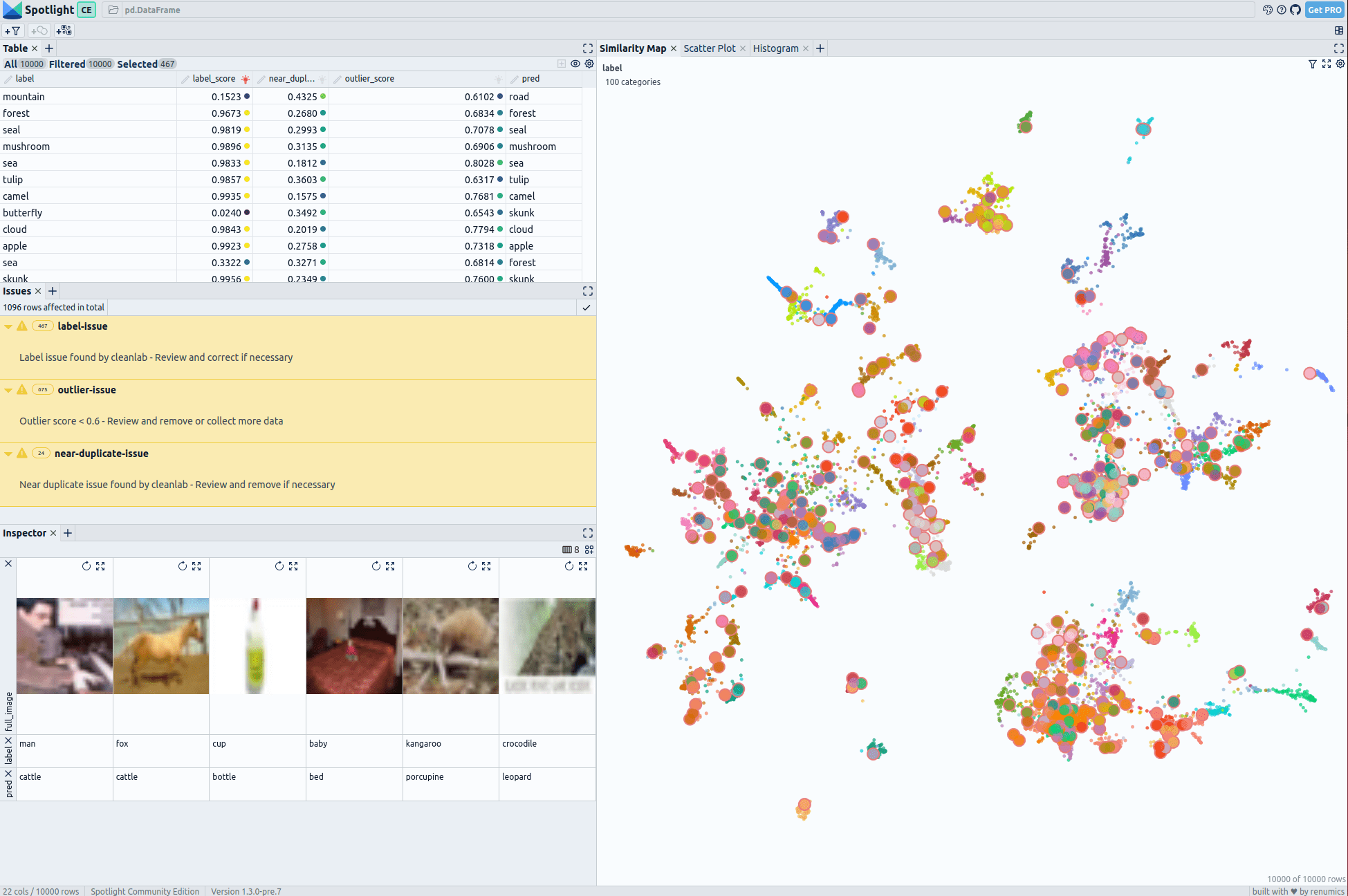
Проблемы с ярлыками
Если мы нажмем «проблема с этикеткой» в таблице проблем, мы сможем просмотреть все проблемы с этикеткой, выявленные Cleanlab, например, крупный рогатый скот, ошибочно помеченный как лиса. Карта сходства является ценным инструментом для улучшения нашего процесса обзора. Выбирая окружающие примеры на этой карте, мы можем получить представление о соседних примерах и найти устойчивые шаблоны ошибок. Кроме того, с помощью интерактивной статистической визуализации, такой как гистограммы, мы можем лучше понять природу и частоту этих проблем.

Использование этих инструментов улучшает идентификацию и понимание проблем с этикетками. Их интеграция подчеркивает эффективность визуализации при обработке обнаруженных проблем.
Выбросы
Если мы нажмем «выбросы» в таблице проблем, мы сможем изучить все аномалии, обнаруженные Cleanlab, такие как полоса тигра, помеченная как тигр. Карта подобия здесь также играет важную роль, позволяя нам увидеть, как эти выбросы связаны с более типичными точками данных. Сосредоточив внимание на этих отклонениях на карте, мы можем распознать закономерности и оценить их значимость. Более того, использование интерактивной статистической визуализации, такой как гистограммы, может пролить свет на распределение и крайность этих выбросов.

Дубликаты
Если мы нажмем «почти повторяющиеся проблемы» в таблице проблем, нам будут представлены все повторяющиеся экземпляры, идентифицированные Cleanlab. Например, мы можем найти изображение, отнесенное к категории «тюлень» и «выдра» в наборе данных. Карта подобия оказывается здесь бесценной, иллюстрируя близость этих дубликатов к их оригинальным аналогам. Отмечая эти совпадения на карте, мы можем определить избыточность и оценить ее последствия. Кроме того, интерактивная статистическая визуализация, такая как гистограммы, может помочь выяснить частоту и кластеризацию этих дубликатов.

Заключение
Сочетание сильных сторон Cleanlab и Spotlight позволяет нам обнаруживать и анализировать потенциальные проблемы с данными. Этот подход позволяет нам ориентироваться в несоответствиях меток, выбросах и почти дубликатах в нашем наборе данных.
У вас есть проблемы с данными в вашем наборе данных? Используйте описанные здесь методы Cleanlab и Spotlight, чтобы определить и просмотреть их. Примените эти инструменты к своим собственным данным и сделайте шаг к более надежному анализу.
Я профессионал с опытом создания передовых программных решений для интерактивного исследования неструктурированных данных. Я пишу о неструктурированных данных и использую мощные инструменты визуализации для анализа и принятия обоснованных решений.
Рекомендации
[1] Алексей Досовицкий, Лукас Бейер, Александр Колесников, Дирк Вайссенборн, Сяохуа Чжай, Томас Унтертинер, Мостафа Дегани, Матиас Миндерер, Георг Хейгольд, Сильвен Гелли, Якоб Ушкорейт, Нил Хоулсби, Изображение стоит 16x16 слов: Трансформеры для изображения Признание в масштабе (2020), arXiv
[2] Кертис Г. Норткатт, Аниш Атали, Джонас Мюллер Повсеместные ошибки меток в наборах тестов дестабилизируют тесты машинного обучения (2021), arXiv