
Прежде чем мы углубимся в тонкости классификации нулевых выстрелов, важно отметить, что в этой статье рассматривается теория, стоящая за концепцией.
Если вы ищете практическое руководство по реализации нулевой классификации в Python, смело переходите к моему руководству «Внедрение нулевой классификации в Python: пошаговое руководство. -Пошаговое руководство»».
В противном случае читайте дальше, чтобы понять основы обучения с нуля.
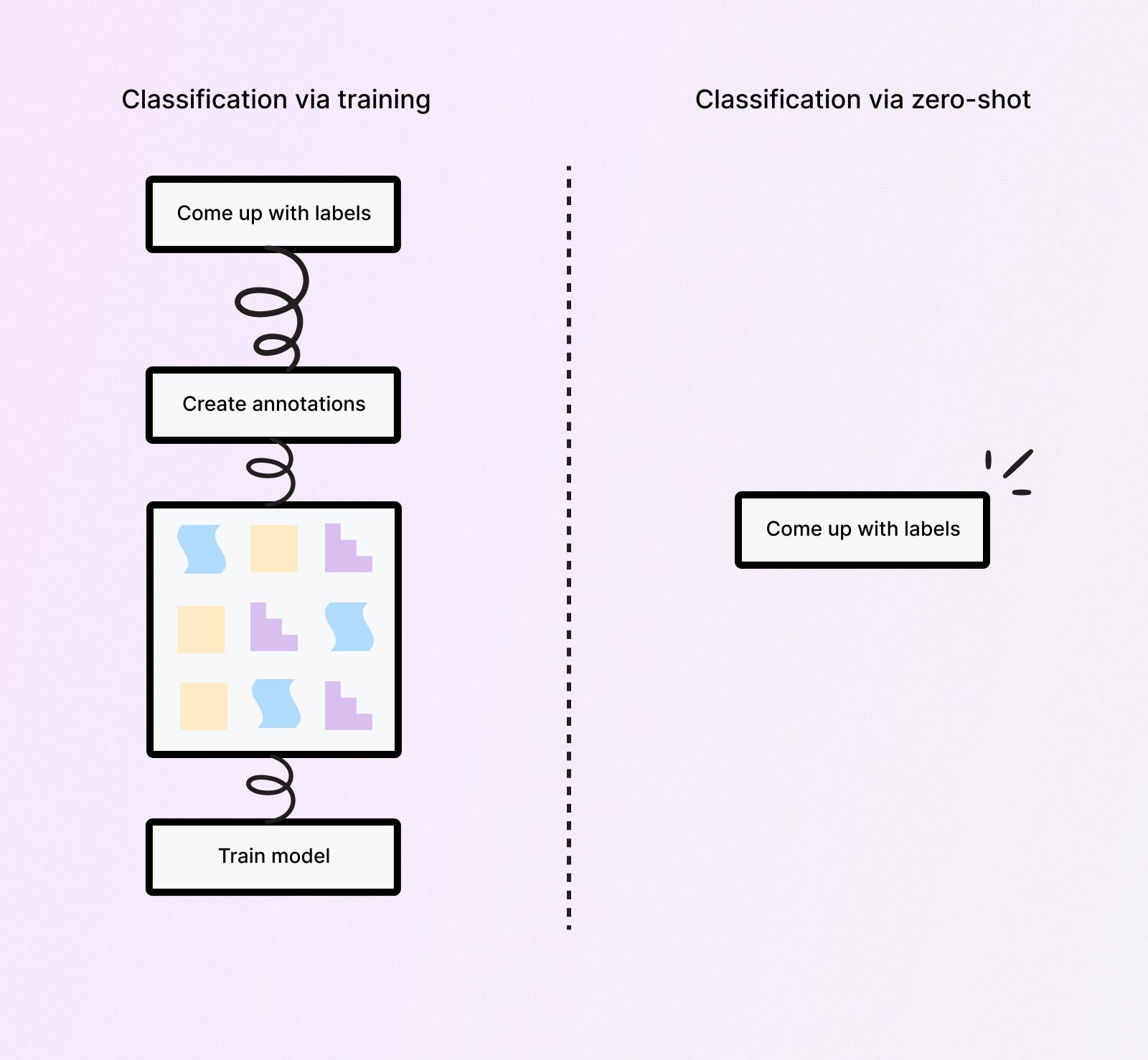
В машинном обучении классификация является центральной задачей, где модели обучаются прогнозировать предопределенные категории или классы заданных точек данных. Но традиционные методы классификации имеют ограничения, особенно при работе с новыми, неизвестными классами или в ситуациях, когда не хватает помеченных данных. Чтобы решить эту проблему, мы рассматриваем инновационный метод, известный как классификация Zero-Shot.
В этой статье мы углубимся в мир Zero-Shot Classification, метода, который позволяет моделям машинного обучения обрабатывать и классифицировать данные по категориям, с которыми они не сталкивались во время обучения. Мы рассмотрим, как он предлагает разительный контраст с традиционными подходами к классификации, изучим лежащую в его основе механику и проиллюстрируем ее применение в реальном мире.
Независимо от того, являетесь ли вы экспертом по машинному обучению, начинающим специалистом по данным или техническим энтузиастом, мы приглашаем вас присоединиться к нам в этом исследовании Zero-Shot Classification — захватывающей области машинного обучения.
Ограничения традиционных подходов к классификации
Традиционные методы классификации, какими бы мощными и полезными они ни были, имеют определенные присущие им ограничения. Среди них зависимость от аннотированных данных и проблемы, возникающие при добавлении новых категорий, выделяются как ключевые камни преткновения.

Необходимость аннотированных данных
В стандартной задаче классификации модели машинного обучения требуют больших объемов аннотированных данных для обучения. Аннотированные данные относятся к наборам данных, в которых каждый экземпляр или пример был помечен или помечен правильным классом или категорией. Это помогает модели изучить отличительные черты, связанные с каждым классом. Затем модель использует эти изученные функции для прогнозирования класса невидимых экземпляров данных.
Однако получение таких аннотированных данных часто может быть сложным, трудоемким и дорогостоящим. Это связано с тем, что обычно требуется, чтобы эксперты в предметной области вручную просматривали и присваивали правильную метку каждой точке данных, что часто невозможно при работе с массивными наборами данных. В некоторых областях, таких как медицинская визуализация или предсказание редких событий, получение достаточного количества размеченных данных для каждой категории особенно сложно из-за редкости определенных состояний или событий.
Испытания с новыми категориями
Еще одно серьезное ограничение традиционных методов классификации проявляется, когда необходимо добавить новые категории или классы в модель после ее обучения. Когда это происходит, модель, по сути, должна быть переобучена с нуля на новом наборе данных, который включает примеры из новых категорий. Это дорого с точки зрения вычислений и практически неудобно, особенно в сценариях, где необходимо часто добавлять новые классы.
Более того, когда модель встречает на этапе прогнозирования новый класс, на котором она не обучалась, она не способна правильно его классифицировать. Это может привести к значительному падению производительности и может ограничить применимость этих моделей в динамических реальных сценариях, где набор возможных классов может меняться или расширяться с течением времени.
В следующих разделах мы увидим, как концепция Zero-Shot Classification может помочь нам преодолеть некоторые из этих проблем и расширить возможности моделей классификации.
Понимание механики классификации Zero-Shot
Классификация Zero-Shot предлагает интересный обходной путь для ограничений традиционных методов классификации. Это достигается за счет использования семантических отношений между классами и использования передачи знаний от видимых к невидимым классам, что позволяет моделям делать прогнозы относительно данных, принадлежащих категориям, с которыми они никогда не сталкивались во время обучения.
Как работает классификация Zero-Shot
В Zero-Shot Classification ключ заключается в способности модели понимать отношения и сходства между различными классами, даже если некоторые из этих классов не присутствовали в обучающих данных. Это достигается путем встраивания как классов, так и экземпляров данных в общее многомерное пространство, часто называемое «пространством встраивания». Затем расстояние или сходство в этом пространстве информирует модель о решении о том, к какому классу, вероятно, принадлежит конкретный экземпляр.
Классы часто представлены их текстовыми описаниями, а вложения классов могут быть получены с помощью предварительно обученной языковой модели для кодирования этих описаний в вектор фиксированной длины. Чем ближе вложение экземпляра данных к встраиванию класса в это пространство, тем больше вероятность, согласно модели, что экземпляр принадлежит этому классу. Этот механизм позволяет модели, обученной с использованием обучения с нулевым выстрелом, классифицировать экземпляры данных по классам, которых не было в ее обучающих данных.
Использование обработки естественного языка (NLP) и встраивания
Успех Zero-Shot Classification в значительной степени зависит от достижений в области обработки естественного языка (NLP) и использования вложений.
Встраивания преобразуют классы или экземпляры данных в плотные векторы фиксированного размера. Они могут фиксировать богатые семантические значения и отношения между данными. Например, вложения слов в НЛП способны фиксировать семантические и синтаксические отношения между словами, так что подобные слова имеют вложения, которые близки друг к другу в многомерном пространстве.
Модели NLP, особенно модели на основе Transformer, такие как BERT или GPT, продемонстрировали впечатляющие возможности в создании таких вложений. Когда дело доходит до классификации Zero-Shot, эти модели помогают создавать осмысленные вложения для классов на основе их текстовых описаний. Это позволяет модели понимать и сравнивать классы, которые она никогда раньше не видела, что позволяет классифицировать новые, невидимые классы.
В следующем разделе мы увидим, как эта уникальная способность классификации Zero-Shot применяется для решения реальных проблем.
Применение нулевой классификации в реальных условиях
Классификация с нулевым выстрелом нашла применение во множестве реальных сценариев, представляя инновационные решения проблем, которые ранее были сложными из-за отсутствия достаточного количества размеченных данных. Здесь мы рассмотрим некоторые из этих приложений и потенциальные преимущества, которые они предлагают.
- Классификация текстов и анализ тональности
В области обработки естественного языка нулевая классификация использовалась для задач классификации текста, где предопределенных меток мало или их не существует. Например, перед моделью может быть поставлена задача классифицировать отзывы клиентов по различным темам, таким как «качество продукта», «служба доставки» или «поддержка клиентов», даже если она никогда не обучалась этим категориям. Точно так же нулевая классификация может использоваться в анализе настроений, позволяя модели понимать и классифицировать нюансы настроений, на которых она не обучалась.
- Распознавание изображений и видео
Нулевая классификация также играет важную роль в задачах распознавания изображений и видео. Рассмотрим сценарий, в котором модель обучается распознавать различные виды животных. Используя обучение с нулевым выстрелом, модель потенциально может распознавать виды, которые не были частью ее обучающего набора, просто на основе описания или атрибутов, связанных с этим видом.
- Медицинская диагностика
В медицинской диагностике, где получение помеченных данных для каждого потенциального состояния может быть трудным и трудоемким, классификация с нулевым выстрелом предлагает многообещающее решение. Модель можно обучить известным заболеваниям с их симптомами и, используя нулевую классификацию, потенциально диагностировать редкие или новые заболевания на основе сходства симптомов.
Потенциальные преимущества
Применение нулевой классификации имеет значительные преимущества. Прежде всего, это позволяет моделям машинного обучения обрабатывать и адаптироваться к новизне и изменениям в сценариях реального мира. Это устраняет необходимость в исчерпывающих маркированных наборах данных для каждого класса, тем самым экономя время, усилия и ресурсы при аннотации данных. Более того, он может повысить гибкость и масштабируемость моделей машинного обучения, сделав их более применимыми и надежными в динамически меняющихся средах.
По мере того, как мы продвигаемся вперед, потенциал нулевой классификации в преобразовании нашего подхода к задачам машинного обучения становится все более очевидным. Тем не менее, как и любая технология, она не лишена собственного набора проблем, которые мы рассмотрим в следующем разделе.
Проблемы и ограничения классификации Zero-Shot
Хотя нулевая классификация дает множество преимуществ для задач машинного обучения, она не лишена своих проблем и ограничений. Двумя ключевыми проблемами являются его зависимость от высококачественных метаданных и возможность неправильной классификации.
Зависимость от качественных метаданных
Одной из фундаментальных предпосылок нулевой классификации является наличие высококачественных, семантически богатых метаданных. При нулевом обучении точная классификация невидимых классов в значительной степени зависит от описаний или атрибутов, связанных с этими классами. Плохо определенные или неточные метаданные могут привести к неправильному встраиванию классов и, как следствие, к неточным прогнозам.
Возможность неправильной классификации
В нулевой классификации существует вероятность неправильной классификации, особенно при работе с классами, которые семантически близки друг к другу. Поскольку предсказания классов основаны на близости вложений классов в многомерном пространстве, классы с похожими описаниями или атрибутами могут иметь вложения, близкие друг к другу, что может привести к путанице.
Несмотря на эти проблемы, область нулевой классификации продолжает развиваться, и исследователи изучают инновационные способы оптимизации производительности и преодоления этих ограничений. Когда мы смотрим в будущее, потенциал классификации с нулевым выстрелом для революционного машинного обучения становится более очевидным, чем когда-либо.
Заключение
В этой статье мы погрузились в увлекательный мир нулевой классификации — метода машинного обучения, расширяющего возможности традиционных классификаторов. Обладая способностью обрабатывать невидимые классы, нулевая классификация открывает захватывающие возможности, особенно в тех областях, где мало размеченных данных.
Мы изучили механику того, как работает нулевая классификация, как она использует вложения и НЛП для понимания семантических отношений, а также ключевые применения этой технологии в классификации текста, распознавании изображений и медицинской диагностике. Несмотря на многообещающие достижения, мы также признали проблемы, с которыми сталкивается нулевая классификация, такие как зависимость от высококачественных метаданных и потенциальная неправильная классификация.
Хотя в этой области еще многое предстоит изучить и улучшить, нулевая классификация, несомненно, обладает большим потенциалом для будущего машинного обучения.
Рекомендации
- Палатуччи, М., Померло, Д., Хинтон, Г. Э., и Митчелл, Т. М. (2009). Обучение с нулевым выстрелом с помощью семантических выходных кодов. В Достижениях в области нейронных систем обработки информации (стр. 1410–1418). "Связь"
- Сочер, Р., Ганджу, М., Мэннинг, К.Д., и Нг, А. (2013). Обучение с нуля благодаря межмодальному переносу. В Достижениях в области нейронных систем обработки информации (стр. 935–943). "Связь"
- Сиань, Ю., Ламперт, Ч. Х., Шиле, Б., и Аката, З. (2019). Обучение с нуля — всесторонняя оценка хорошего, плохого и уродливого. Транзакции IEEE по анализу шаблонов и машинному интеллекту, 41(8), 2251–2265. "Связь"
- Девлин, Дж., Чанг, М.В., Ли, К., и Тутанова, К. (2019). BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка. В материалах конференции 2019 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка. "Связь"
- Браун, Т. Б., Манн, Б., Райдер, Н., Суббиа, М., Каплан, Дж., Дхаривал, П., … и Агарвал, С. (2020). Языковые модели учатся нечасто. В Достижениях в области систем обработки нейронной информации (стр. 1877–1901). "Связь"