CovNets — это своего рода сеть, которая использует набор фильтров для фильтрации информации; сбросьте все, что не имеет значения, и оставьте только самые важные шаблоны для задачи. Эта новая концепция доминирует в области компьютерного зрения примерно с 2015 года. На первый взгляд концепция кажется простой: с помощью набора фильтров, называемых ядрами, можно активировать другую часть изображения, обнаруживая соответствующие закономерности. Использование этих фильтров составляет основную операцию блока в модели компьютерного зрения.
ConvNets может научиться:
- Шаблоны, которые являются инвариантными к переводу.
- И пространственные иерархические шаблоны.
Шаблоны инвариантности перевода:
Если наша сеть обнаруживает шаблон в левом нижнем углу изображения, и такой же может быть в правом верхнем углу, этот шаблон тот же, но в другом месте, мы сможем обнаружить его независимо от местоположения.
Пространственные иерархические модели:
Изображение состоит из нескольких паттернов; например, когда мы изучаем геометрию, мы начинаем с основных элементов евклидовой геометрии, сначала с точки, затем с линии, затем с треугольника и так далее. Они представлены в иерархии. Этот случай ничем не отличается; сначала у нас есть шаблоны границ, а затем мы переходим к сложным представлениям конкретной информации о домене, к которому мы применяем эти фильтры.
Если эти характеристики применимы к нашей проблеме, мы можем применить эту технику к нашей проблеме! Это естественно для изображений, поэтому эти сети достигают такого успеха.
Свертка: ключевые концептуальные изображения и фильтры
Я постараюсь доступно объяснить, как работает операция свертки. Хотя необходимы некоторые предварительные знания алгебры, я буду упрощать или хотя бы пытаться ;). Потерпите, дальше будет интереснее, обещаю.
Чтобы объяснить это, нам нужно пересмотреть нашу концепцию изображения, и я должен рассказать вам, что такое фильтр.
Во-первых, что такое образ и как мы можем его интерпретировать, чтобы с ним работать?
Цветное изображение состоит из комбинации трех цветов, которые мы называем каналами RGB. Красный, зеленый и синий. Мы кодируем цвета числами от 0 до 255 для каждого канала, чем больше число, тем больше вклад этого канала в окончательный цвет этого изображения, ноль означает, что в этом канале нет цвета. Когда мы работаем с этим изображением на компьютере, мы видим его как матрицу, вы можете думать об этом как о таблице, в данном случае о 3 таблицах, образующих куб.
Я покажу вам, что я имею в виду под этим:
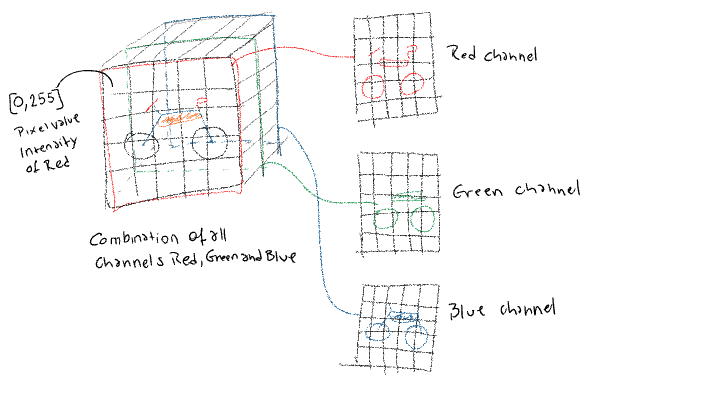
Как вы можете видеть, черные колеса присутствуют во всех каналах, именно так черный цвет формируется на окончательном изображении путем смешивания всех цветов, все каналы имеют одинаковый вклад, и в данном случае это 255 для формирования. черный. Затем у нас есть корпус велосипеда, который присутствует только в синем канале, поскольку он чисто синий, то же самое с рулем и сиденьем. Оранжевая часть, свисающая с корпуса, имеет вклад от всех каналов.
Давайте посмотрим на эти фильтры!
Наш последний компонент, необходимый для применения операции свертки, — это фильтры или ядра (помните, что мы должны использовать причудливое имя, чтобы оно звучало круто при разговоре со случайными людьми на дискотеке). Но что это? Ну, это тоже набор матриц, опять же, вы можете думать о них как о таблицах. В общем, маленькие, такие как 5 на 5, 3 на 3 или 7 на 7, а также 1 на 1 используются в некоторых конкретных случаях. Да, они все квадратного размера.

Наконец, у нас есть все, чтобы объяснить, что такое операция свертки! Столько тайн, черт возьми… мы почти закончили, не отставайте от меня еще немного.
Операция свертки
На каждом шаге мы будем умножать ядро на участок изображения для всех каналов в одной и той же позиции. После суммируем его и сокращаем до 1 числа. Это будет результат операции свертки. После этой операции мы применяем функцию активации, такую как, например, ReLu, которая избавится от отрицательных значений. Затем мы перемещаем фильтр на одну позицию вправо и делаем тот же процесс, когда мы доходим до конца, спускаемся на одну строку вниз и повторяем, пока не охватим все изображение!
Эти частичные результаты станут частью карты признаков, которая продвинет сеть к следующему сверточному блоку. В итоге у нас будет столько карт объектов, сколько фильтров у нас есть. Это то, что вам нужно принять во внимание, так как это увеличит количество параметров, которые сеть должна будет изучить.
Чтобы показать процесс, я буду использовать ядро 3 на 3. Это ядро будет активироваться на вертикальных линиях. В итоге получается карта объектов, где вертикальные границы более четкие. В этом примере я использую изображение RGB с ненормализованными значениями.
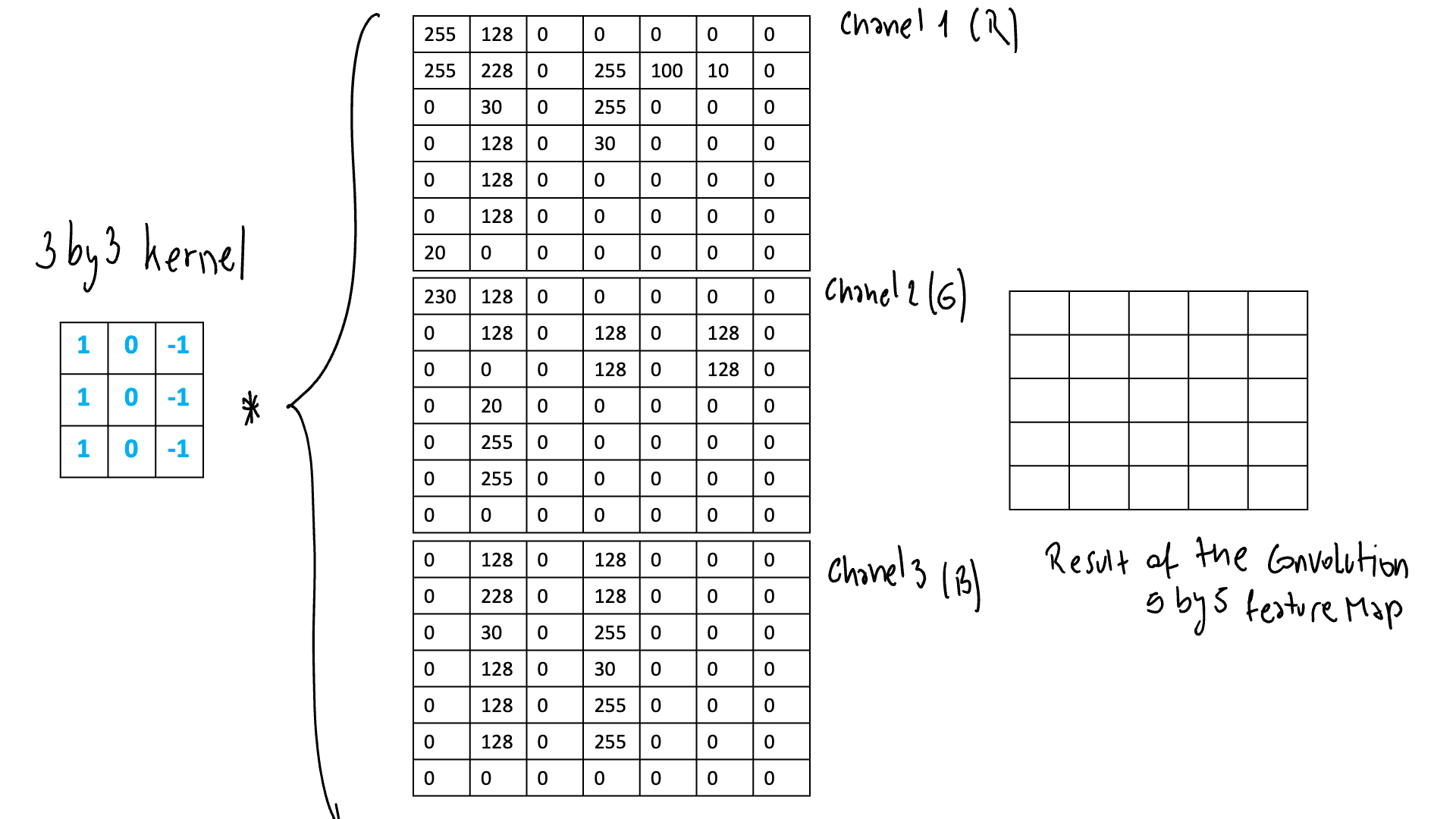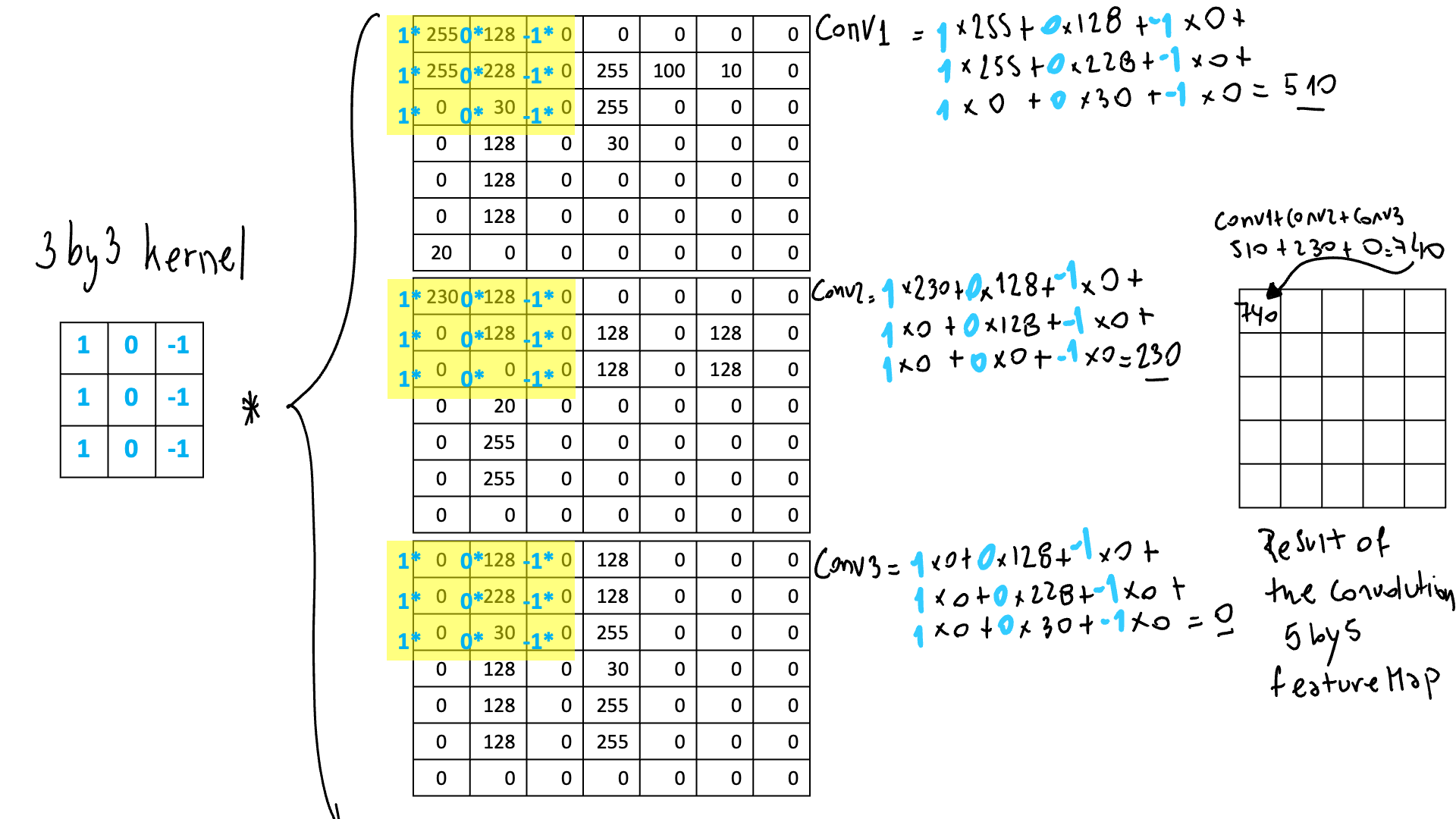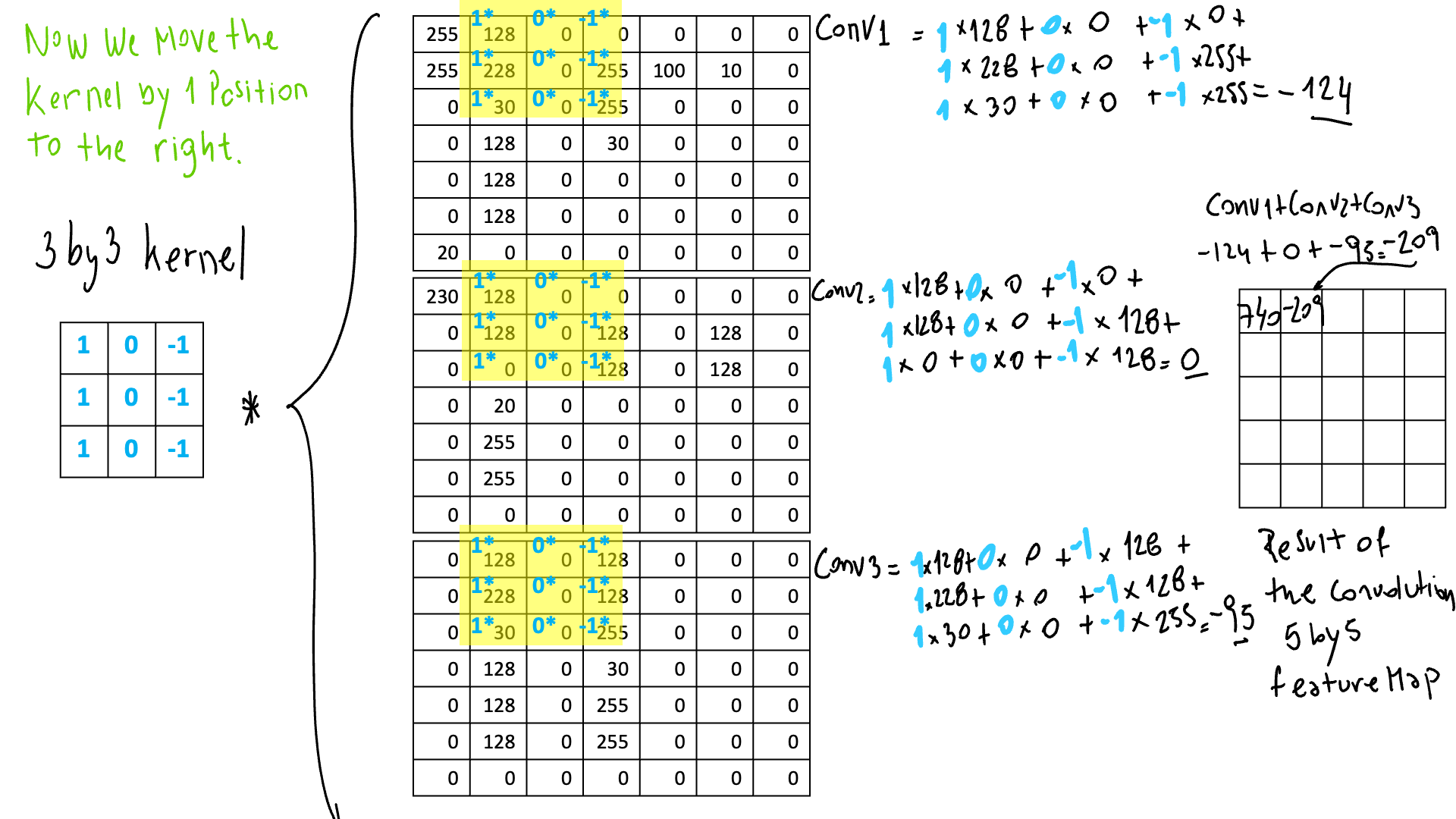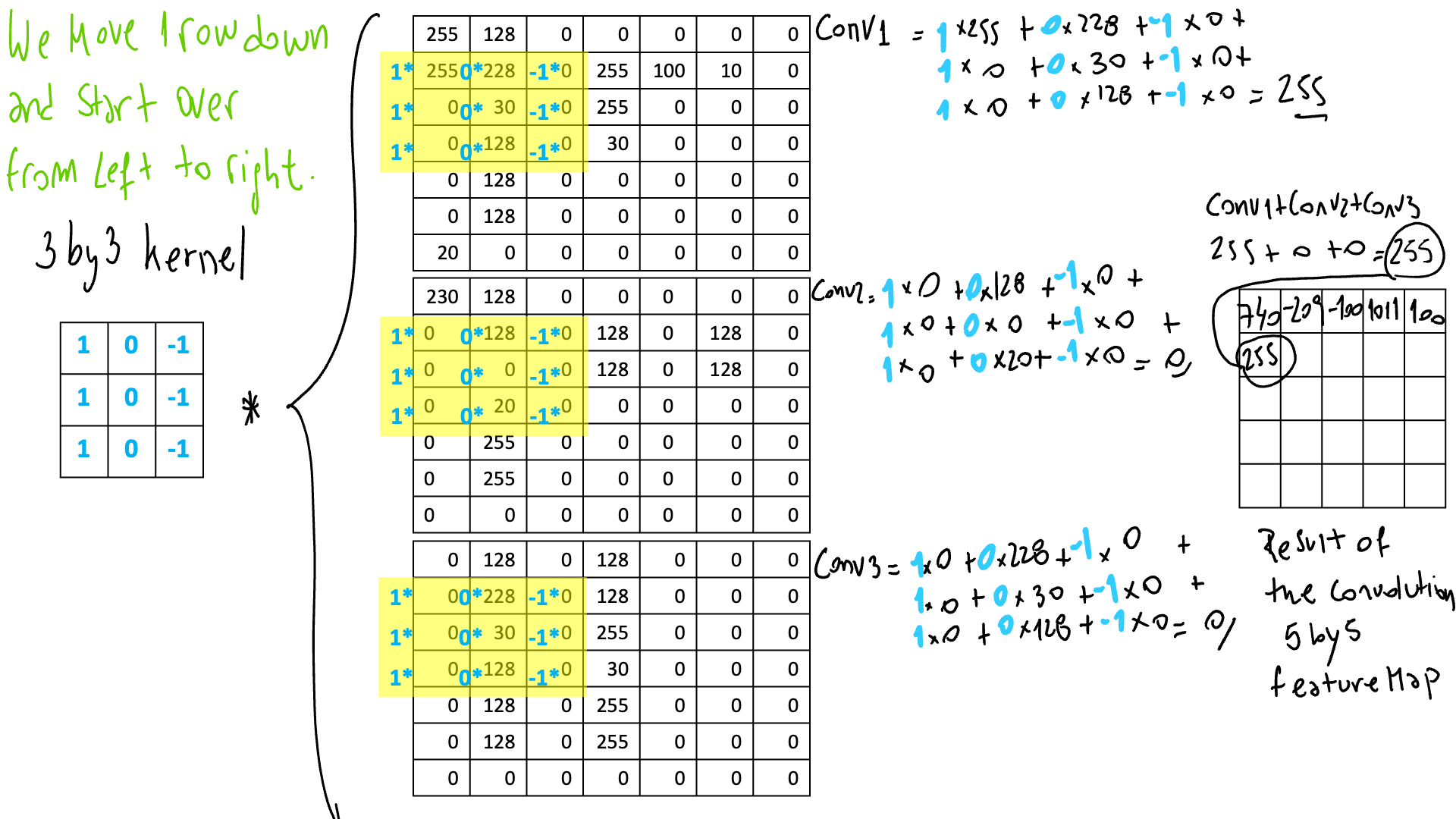
После того, как мы применим ту же операцию ко всем участкам изображения, у нас получится наша первая карта признаков! У нас будет столько карт объектов, сколько фильтров у нас есть на этом этапе.
Я хочу рассказать о другом свойстве этой методики — трансляционной инвариантности. Неважно, где находится вертикальная линия, насколько мы ее нашли там, она может быть где угодно, и нас это не волнует.
Как видите, карта объектов меньше, чем исходное изображение. Это будет в том случае, если вы не дополните изображение строкой или столбцом нулями. Иногда важно сохранить одинаковый размер, и вам нужно будет это сделать. В этом случае мы перемещаем ядро на одну позицию за раз. В некоторых случаях вам нужно будет переместить более 1. В нашем примере у нас есть изображение 7 на 7, и на выходе получается карта объектов 5 на 5.
Размер результата можно рассчитать заранее с помощью этого уравнения:

С шагом 1 и размером ядра 3 мы можем получить карту функций того же размера, что и входные данные с отступом = 1.
Пример простой ConvNet, состоящей из блоков сверток
Перед этим еще один элемент:
Поскольку мы собираемся увеличивать количество фильтров по мере продвижения в сети, и эти карты функций будут содержать, скажем, более важные функции. Существует процесс, который применяется в конце каждого набора сверточных блоков, то есть максимальное и среднее объединение. Как правило, это фильтры 2 на 2. В случае максимального объединения идея состоит в том, чтобы сохранить только максимальное значение этой матрицы 2 на 2, затем мы перемещаем 1 позицию вправо в конце, мы делаем это для следующего row, и в итоге мы получим карту объектов вдвое меньшего размера. Пул среднего значения — это та же процедура, но вместо сохранения максимального значения мы сохраняем среднее значение в матрице 2 на 2.
Это процесс максимального объединения

Простая конвнет
Я рассказал вам о других характеристиках этих сетей, а именно о том, что они могут изучать пространственные иерархические модели. Я схематично покажу, что происходит, когда мы расставляем эти фильтры, что получается на выходе и чего мы можем ожидать по мере углубления. Это просто представление на примере картинки с велосипедом.

В конце вы можете заметить слой Flatten, который должен позже передать эту карту объектов, теперь вектор в полностью связанный слой, который сможет работать с этими значениями.
В конце концов, ConvNets способны изучать любой паттерн в любом месте и в то же время изучать пространственные иерархические паттерны по мере того, как мы погружаемся глубже. Сначала мы могли бы ожидать, что сеть изучит базовые шаблоны, такие как границы, по мере того, как мы приближаемся к концу сети, мы могли бы ожидать более сложные, такие как компоненты, специфичные для нашей области, в данном случае колесо или сиденье. Подробнее далее во 2 части! Оставайтесь с нами…