Чаще всего наши корпоративные платформы предназначены для разработки традиционных программных приложений. Обычно они состоят из четырех сред — Dev, Test, Pre-Prod и Prod — где среды становятся все более безопасными по мере прохождения через них.
Таким образом, «Dev» или «Разработка» — это наиболее либеральная из зон, где разработчики обычно могут делать все, что им заблагорассудится, а, с другой стороны, «Prod» или «Производство» — это бесконтактная зона и, как правило, единственное место, где могут находиться оперативные данные. .
Однако эти среды, как правило, не подходят для создания и выпуска продуктов данных. Под «продуктами данных» мы подразумеваем приложения, в которых данные и код тесно связаны и зависят друг от друга. Модели машинного обучения являются ярким примером; где специалисты по данным начинают свой жизненный цикл с изучения живых данных и где параметры модели зависят от данных, на которых они обучались.

В этих сценариях необходимы необработанные (неанонимизированные) данные в масштабе, чтобы можно было идентифицировать реальные тенденции и корреляции с несколькими переменными, чтобы можно было объединить данные из нескольких исходных систем и чтобы этические проверки, такие как обнаружение предвзятости, могли происходит.
Синтетические или анонимные данные здесь не подходят, особенно в крупных организациях с несколькими областями бизнеса, где разные модели данных, хранилища, инфраструктура и устаревшие системы усложняют эту среду. Иметь актуальные обезличенные данные, поддерживающие ссылочную целостность и статистические взаимосвязи между многими миллионами записей, тысячами полей и сотнями разрозненных исходных систем, на самом деле невозможно.
Попытка заставить программный RTL работать с данными
Как только организации признают, что им нужно будет работать с оперативными данными, они пытаются навязать существующее программное обеспечение RTL, загоняя квадратный колышек в круглую дыру, и в конечном итоге выбирают один из двух вариантов:
- Проталкивание данных в более низкие среды, где происходит разработка; или
- Подталкивание разработки к более высоким средам, где находятся живые данные
Первый вариант означает введение новых рисков, потому что ваши данные вышли из стального кольца Production и теперь находятся в менее контролируемой среде, что особенно опасно в общедоступном облаке. На хорошо управляемых предприятиях это также будет включать отказ от данных в зависимости от варианта использования, что затрудняет масштабирование.
Второй вариант означает введение пользователей-людей и новых инструментов в то, что раньше было жестко контролируемой средой, где все приложения работали под учетными записями служб. У вас также могут быть законные опасения по поводу работы по разработке или мошеннического запроса, который теперь влияет на критически важную для бизнеса рабочую нагрузку.
Из двух вариантов второй, вероятно, является меньшим злом, если вы можете ввести некоторые элементы управления, чтобы изолировать действия сборки от рабочих нагрузок, используя, например, очереди ресурсов.
Но какое решение лучше?
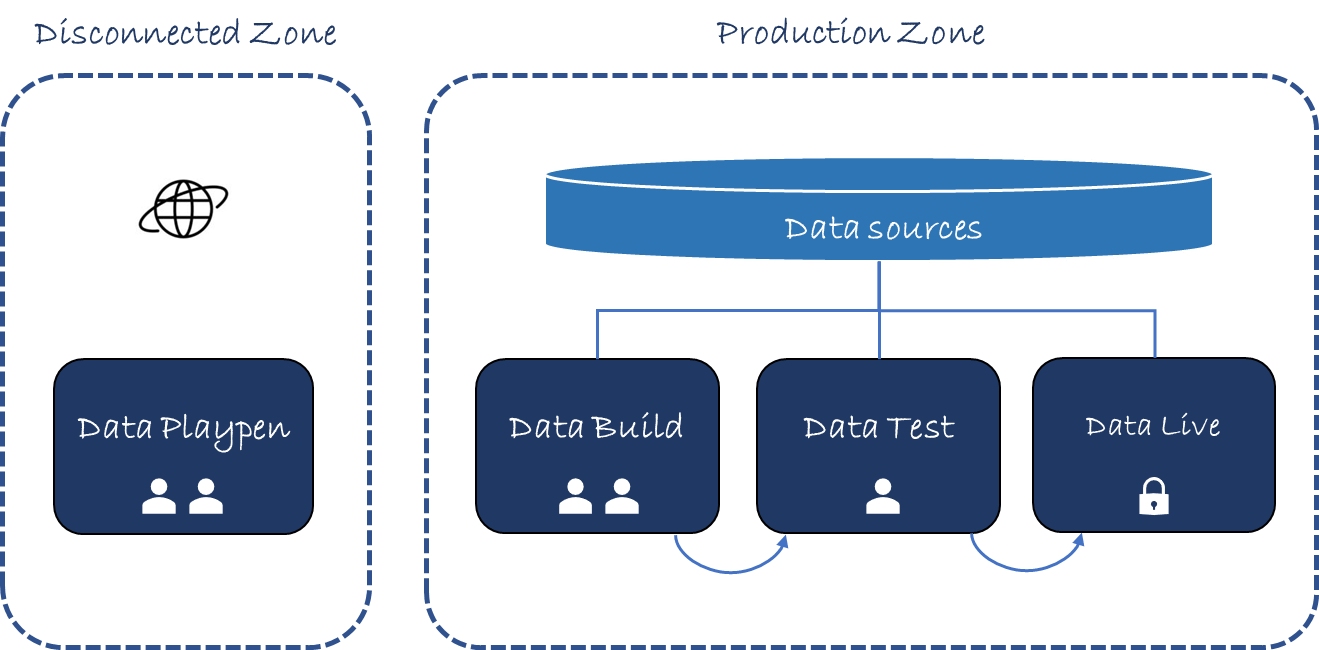
В стальном кольце Production, определяемом сетевой сегрегацией, создайте три совершенно новые среды, образующие новый Путь данных к жизни:
- Сбор данных
- Тест данных
- Данные в реальном времени
Создание данных обеспечит доступ человека, интерактивные сеансы, в ходе которых данные в реальном времени могут быть опрошены в масштабе с помощью ряда инструментов и где могут быть созданы продукты данных. Это ваша среда EDA (Exploratory Data Analytics).
В рамках тестирования данных вновь созданные информационные продукты будут подвергаться целому ряду тестов, включая тестирование производительности и этических норм. Здесь вам понадобится гораздо меньше инструментов разработчика, так как здесь просто проводятся окончательные проверки перед развертыванием. Если проверки не пройдены, вы возвращаетесь к сборке данных, чтобы выполнить исправления, прежде чем вернуться сюда.
Data Live увидит, что продукты данных работают как приложения под учетными записями служб, а среда будет свободна от инструментов (или доступа человека), за исключением возможностей мониторинга. Эти возможности мониторинга будут способны к действиям, связанным с данными, таким как обнаружение дрейфа данных.
В этих трех средах исходные данные предприятия являются одним и тем же активом. Нет дублирования или копирования данных, если только вы не работаете в особенно неэластичной среде. При таком подходе конвейерам вашей среды нужно только продвигать код через среды.
Возможно, есть необходимость в одной последней среде: манеже или экспериментальной зоне. Здесь разработчики имеют полную свободу, включая доступ в Интернет.
4.Детский манеж данных
Детский манеж данных отключен от остальной части Data RTL через сетевую сегрегацию и, действительно, возможно, отключен от остальной части вашего предприятия. Это испытательный полигон для новых инструментов или методов, независимо от данных или, возможно, с синтетическими данными. Работа в этой среде будет способствовать формированию мышления, а не будет первым шагом в создании информационного продукта.
Как могут сосуществовать RTL программного обеспечения и RTL данных?
Большинству современных предприятий потребуются оба RTL, особенно если они хотят использовать расширенную аналитику, и хорошая новость заключается в том, что они могут относительно аккуратно сосуществовать в рамках одной платформы:

Существует момент принятия решения о том, что «Data Live» и «Prod» на самом деле являются одной и той же средой или двумя отдельными средами, потому что на этом этапе жизненного цикла продукт данных можно рассматривать как отдельное приложение, работающее под учетной записью службы. Это потребует изучения, но если вы добавляете новый RTL данных к существующей платформе с существующим RTL программного обеспечения, вероятно, будет проще избежать их объединения в одну среду.
Наконец, иногда будут сценарии, в которых разработчики данных будут создавать компоненты разработки программного обеспечения, которые будут поддерживать сборку или обслуживание их продуктов данных. Это может быть настраиваемый пакет или хранилище аудита, в котором регистрируются входные и выходные данные модели данных.
Здесь вы можете увидеть слияние двух RTL, начиная с RTL программного обеспечения Dev, Test, Pre-Prod, но затем одновременно наблюдая за выпуском в Data Build, Data Test и Data Live, поэтому артефакт доступен для новой работы по сборке данных.
Помните, что Data RTL предлагает привилегированный доступ, который не следует распространять за пределы определенных членов вашей организации, которые должны выполнять определенные действия, связанные с доступом человека к оперативным данным.
Среди этих пользователей будут такие, как ваши ученые и специалисты по анализу данных, а также те, кому необходимо тестировать приложения на реальных данных, чтобы обеспечить справедливые результаты для клиентов.
Если данные и код независимы, разработчики всегда должны использовать RTL программного обеспечения.