Эта статья изначально была опубликована в блоге Encord, который вы можете прочитать здесь.

Фредерик Хвилшой
Наиболее очевидным преимуществом использования синтетических обучающих данных является то, что они могут дополнять наборы данных, в которых в противном случае не было бы достаточного количества примеров для обучения модели. Как правило, чем больше обучающих данных более высокого качества, тем выше производительность, поэтому синтетические данные могут сыграть чрезвычайно важную роль для инженеров по машинному обучению, работающих в областях, которые страдают от нехватки данных.
Однако использование синтетических данных имеет свои плюсы и минусы. Давайте рассмотрим некоторые преимущества и недостатки использования синтетических обучающих данных.
Преимущества синтетических обучающих данных
Помогает решить проблемы пограничных случаев и смещения данных
Когда модели с высокими ставками, такие как те, которые используются для запуска автономных транспортных средств или диагностики пациентов, работают в реальном мире, они должны иметь возможность справляться с крайними случаями. Однако, поскольку крайние случаи по своей природе являются выбросами, поиск достаточного количества реальных примеров для обучения модели иногда может показаться поиском иголки в стоге сена. С синтетическими данными поиск окончен.
Например, подумайте об инженерах по машинному обучению, обучающих модель диагностировать редкое генетическое заболевание. Поскольку это заболевание встречается редко, реальная выборка пациентов, у которых можно собрать данные, вероятно, слишком мала для эффективного обучения модели. Генерация синтетических данных может обойти проблему создания большого набора данных из небольшой выборки.
Та же самая логика применима к дополнению наборов данных, которые страдают от системной необъективности данных. Например, исторически большая часть медицинских исследований была основана на исследованиях белых мужчин, что приводило к расовым и гендерным предубеждениям в медицине и медицинском ИИ. Кроме того, чрезмерная зависимость от крупных исследовательских институтов в отношении наборов данных увековечила расовую предвзятость. Точно так же чрезмерная зависимость от существующих наборов данных из открытых источников, а также социальное неравенство привели к тому, что программное обеспечение для распознавания лиц работает более точно на белых лицах.
Чтобы избежать сохранения этих предубеждений, инженеры по машинному обучению должны обучать модели на данных, содержащих недопредставленные группы. Дополнение существующих наборов данных синтетическими данными, представляющими эти группы, может ускорить исправление этих ошибок.
Экономия времени и денег за счет дополнений
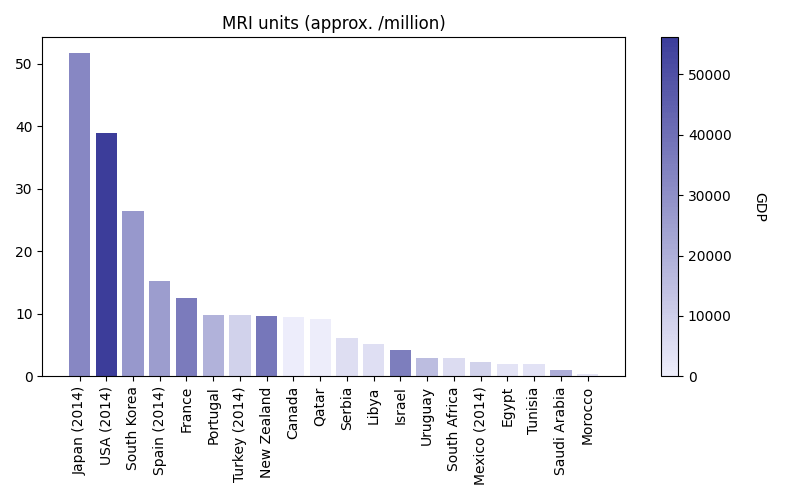
Для областей исследований, где трудно получить данные, использование синтетических данных для расширения наборов обучающих данных может быть эффективным решением, которое экономит время и деньги. Например, исследователи и клиницисты, работающие с МРТ, сталкиваются с множеством проблем при сборе разнообразных наборов данных. Начнем с того, что аппараты МРТ чрезвычайно дороги: типичный аппарат стоит 1 миллион долларов, а передовые модели — до 3 миллионов долларов. В дополнение к оборудованию для этих машин требуются стерильные помещения, исключающие вмешательство извне и обеспечивающие защиту для тех, кто находится за пределами помещения. Из-за этих затрат на установку больница обычно тратит от 3 до 5 миллионов долларов на комплект с одной машиной. По состоянию на 2016 год во всем мире существовало всего около 36 000 машин. Безопасная и эффективная эксплуатация этих машин также требует специальных технических знаний.
Учитывая эти ограничения, неудивительно, что эти машины пользуются спросом, а в больницах есть списки ожидания, полные пациентов, нуждающихся в них для диагностики. Однако в то же время исследователям и инженерам по машинному обучению могут понадобиться дополнительные данные МРТ о редких заболеваниях, прежде чем они смогут обучить модель для точной диагностики пациентов. Дополнение этих наборов данных синтетическими данными означает, что им не нужно заказывать столько дорогостоящего времени МРТ или ждать, пока машины станут доступны, что в конечном итоге снижает стоимость и сроки запуска модели в производство.
Синтетические данные также могут сэкономить деньги и время другими способами. Для редких или региональных заболеваний синтетические данные могут устранить проблемы, связанные с поиском достаточного количества пациентов по всему миру и необходимостью зависеть от их участия в длительном процессе получения МРТ. Возможность расширения наборов данных может особенно помочь уравнять правила игры в ускорении разработки медицинского ИИ для лечения пациентов в развивающихся странах, где ограничения, связанные с медицинским доступом и ресурсами, создают дополнительные проблемы при сборе данных. Для контекста: в 2016 году во всем регионе Западной Африки было всего 84 аппарата МРТ для обслуживания населения в более чем 350 миллионов человек.
Решает вопросы конфиденциальности и расширяет научное сотрудничество
В идеальном мире исследователи должны сотрудничать для создания больших общих наборов данных, но в областях, в которых дефицит данных наиболее распространен, правила конфиденциальности и законы о защите данных часто затрудняют сотрудничество.
Поскольку синтетические данные ненастоящие, технически они никому не принадлежат, что открывает возможность обмена наборами данных между исследователями для улучшения и ускорения научных открытий. Например, ранее в этом году Королевский колледж предоставил исследователям 100 000 искусственно созданных изображений мозга, чтобы помочь ускорить исследования деменции. Сотрудничество на этом уровне в медицинской науке возможно только при использовании синтетических данных.
К сожалению, в настоящее время использование синтетических данных сопряжено с компромиссом между достижением дифференциальной конфиденциальности — стандарта, гарантирующего, что лица в наборе данных не могут быть идентифицированы, — и точностью генерируемых синтетических данных. Однако в будущем публичное распространение искусственных изображений без нарушения конфиденциальности может стать все более вероятным.
Недостатки
Для многих остаются непомерно высокими
Хотя синтетические данные позволяют исследователям избежать затрат на создание наборов данных исключительно из данных реального мира, создание синтетических данных сопряжено с собственными затратами. Время вычислений и финансовые затраты на обучение генеративно-состязательной сети (GAN) — или любой другой генеративной модели на основе глубокого обучения — для создания реалистичных искусственных данных зависят от сложности рассматриваемых данных. Обучение GAN для получения реалистичных данных медицинских изображений может занять недели обучения, даже на дорогостоящем специализированном оборудовании и под наблюдением высококлассных инженеров.
Даже для тех организаций, у которых есть доступ к необходимому оборудованию и ноу-хау, синтетические данные не могут быть панацеей от проблем с наборами данных. GAN — это относительно недавняя разработка, поэтому трудно предсказать, будет ли GAN производить полезные синтетические данные, кроме как методом проб и ошибок. Чтобы следовать стратегии проб и ошибок, организации должны иметь свободное время и деньги.
В результате создание синтетических данных в некоторой степени ограничено учреждениями и компаниями, которые имеют доступ к капиталу, большим объемам вычислительной мощности и высококвалифицированным инженерам по машинному обучению. В краткосрочной перспективе синтетические данные могут помешать демократизации ИИ, отделив тех, у кого есть ресурсы для создания искусственных данных, от тех, у кого их нет.
Риск перетренированности
Даже когда GAN работает правильно, инженеры машинного обучения должны сохранять бдительность, чтобы она не была «перетренирована». Как бы странно это ни звучало, хотя использование синтетических данных может помочь исследователям справиться с проблемами конфиденциальности, оно также может подвергнуть их риску совершения неожиданных нарушений конфиденциальности, если GAN перетренируется.
Если обучение будет продолжаться слишком долго, генеративная модель в конечном итоге начнет воспроизводить данные из исходного пула данных. Этот результат не только контрпродуктивен, но также может подорвать конфиденциальность людей, чьи данные были во время его обучения, путем воссоздания их информации в том, что должно быть искусственным набором данных.
Это, например, настоящее изображение Дрейка?

Нет, это не так. Это синтетическое изображение из этой статьи, где модель глубокого обучения используется для увеличения размера носа Дрейка. Так защищает ли это изображение конфиденциальность Дрейка или нет? Технически это не Дрейк, но все равно явно Дрейк, верно?
Проверка достоверности полученных данных
Поскольку искусственные данные часто используются в областях, где реальных данных мало, существует вероятность того, что сгенерированные данные могут неточно отражать население или сценарии реального мира. Исследователи должны создать больше данных — потому что данных для обучения модели с самого начала было недостаточно, — но затем они должны найти способ поверить в то, что создаваемые ими данные отражают то, что происходит в реальном мире.
Инженеры данных и машинного обучения должны выполнить важный уровень контроля качества после того, как данные будут созданы, чтобы проверить, точно ли новые искусственные данные отражают выборку реальных данных, которые они призваны имитировать.
Нотка оптимизма
Хотя синтетическое обучение сопряжено со своими трудностями и недостатками, его развитие является многообещающим, и оно может произвести революцию в областях, где нехватка наборов данных реального мира замедлила применение машинного обучения. Как и в случае с любой новой технологией, создание синтетических данных будет иметь свои проблемы с ростом, но ее обещание ускорить технологию и положительно повлиять на жизнь многих людей намного перевешивает ее нынешние недостатки.
Команды машинного обучения и обработки данных любого размера используют приложения Encord для совместной работы, функции автоматизации и API-интерфейсы для создания моделей, аннотирования, управления и оценки своих наборов данных. Загляните к нам здесь.