Выявление и оценка юмора и оскорбительности текстов
Задний план
Команда проекта: Уильям Эйвери, Сатья Бодду, Сай Кукунтла, Джин Ли, Линдия Тьюаджа и Логан Уингер
Репозиторий Github: https://github.com/satyaboddu26/EE460J-FinalProject [1]
Анализ настроений — это широко изучаемый метод в области обработки естественного языка, особенно для выявления положительных и отрицательных эмоций. Однако более тонкие выражения эмоций, такие как юмор, представляют собой проблему из-за их диапазона и тенденции к идиосинкразии. Юмористические высказывания могут сильно различаться по качеству: от игры слов и безвкусных острот до ситуационной иронии и «черного» или оскорбительного юмора.
Наш проект фокусируется на нескольких аспектах анализа настроений с помощью юмора. Набор данных и основные цели нашего проекта взяты из SemEval 2021 Shared Task 7 (HaHackathon: Rating Humor and Offence) [2]. Данные для обучения состояли из 8000 коротких текстов (длиной от одного до двух предложений), которые были помечены как юмористические (1) или не юмористические (0). Если текст считался юмористическим, ему присваивался рейтинг юмористичности (0–5) и противоречивости юмористического ярлыка (0 или 1). Юмористический текст является спорным, если его дисперсия оценок юмора выше, чем медиана дисперсии всех текстов. Кроме того, есть рейтинг того, насколько текст оскорбителен (0–5).
Мы сосредоточились на трех подзадачах из Задания 1 конкурса:
- Бинарная классификация того, является ли текст юмористическим или нет (основная часть нашей работы)
- Предсказание юмористичности текста
- Бинарная классификация того, является ли юмористический текст «спорным»
Поскольку этот набор данных содержит большую часть текстовых образцов, которые являются как юмористическими, так и оскорбительными, он совершенно уникален по сравнению с гораздо большими наборами юмористических данных. Хотя мы смогли добиться приемлемой производительности для нашей первой подзадачи (до ~0,89 балла F1), ограничения в данных сделали вторую и третью подзадачи довольно сложными.
Исследовательский анализ данных
Данные содержат 8000 текстов и представлены в следующем формате:
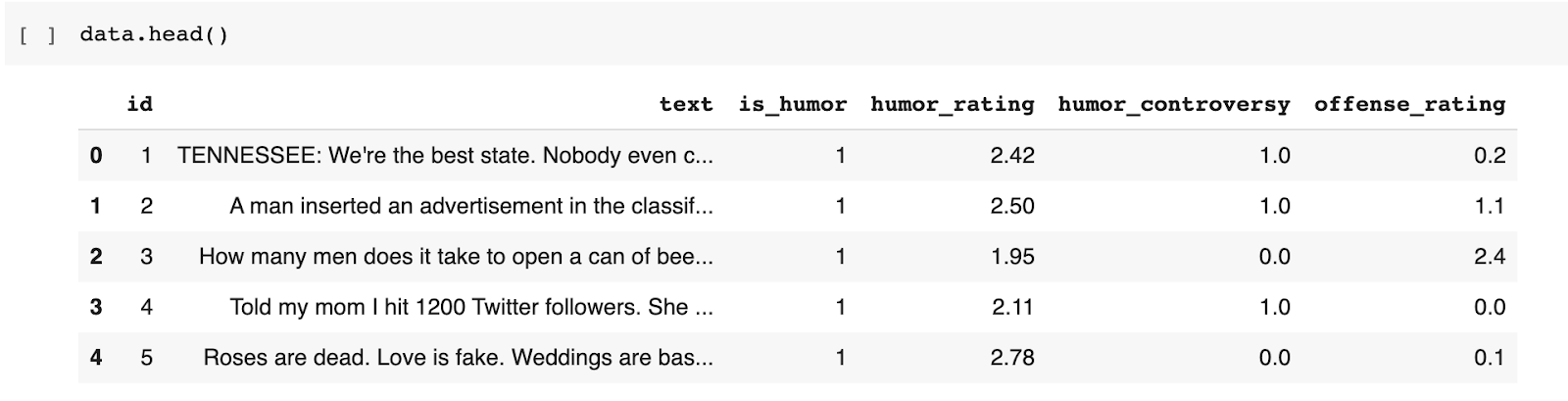
Построив гистограмму данных, мы видим, что почти 5000 из 8000 текстов в обучающей выборке считаются юмористическими.
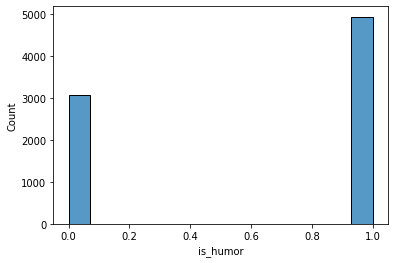
Из юмористических текстов почти половина также считается спорной.
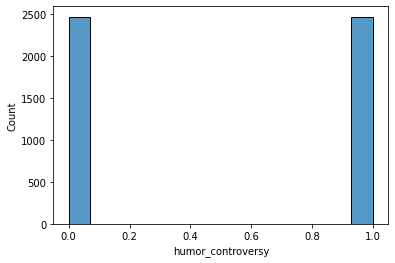
Для поиска трендов и общих слов в текстах, которые считаются юмористическими, мы создали облако слов.
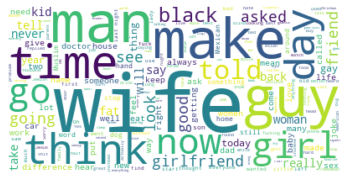
Многие из самых больших слов в облаке слов выше имеют гендерную принадлежность, например, «жена», «мужчина», «парень» и «девушка». Это говорит о том, что юмористические тексты в этом наборе данных часто используют гендерные роли как источник комедии. Сексистские шутки часто считаются оскорбительными или противоречивыми, поэтому мы создали еще одно облако слов из текстов, классифицированных как юмористические и спорные.
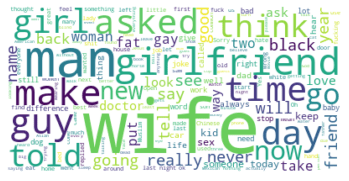
Мы также можем видеть в этом облаке несколько гендерных слов, но они значительно крупнее, что указывает на то, что эти слова чаще встречаются в спорных текстах.
Методы предварительной обработки данных
Нельзя недооценивать важность предварительной обработки данных для машинного обучения, особенно для задач НЛП. Таким образом, мы пробовали различные подходы для преобразования наших текстовых данных в полезные функции. Мы обнаружили, что некоторые «стандартные» подходы НЛП к предварительной обработке, такие как удаление стоп-слов и знаков препинания, не подходили для этой задачи, поскольку часто терялась некоторая информация о тоне утверждения (например, восклицательные знаки).
Word2Vec
Word2Vec использует нейронную сеть для изучения словесных ассоциаций в корпусе текста, представляя каждое отдельное слово в виде вектора. Важно отметить, что векторы слов расположены в векторном пространстве таким образом, что контекстуально похожие слова находятся ближе друг к другу в пространстве. Таким образом, то, насколько близко два вектора слов находятся в векторном пространстве, указывает на уровень семантического сходства в тексте, что позволяет проводить более сложный анализ с помощью других моделей.
Абзац вектор
Вектор абзаца был представлен Куоком Ле и Томасом Миколовым в статье под названием Распределенные представления предложений и документов[3]. Подобно Word2Vec, Paragraph Vector — это алгоритм обучения без учителя, который фиксирует семантическое значение и представляет текстовые данные в виде векторов.
Как и Word2Vec, Paragraph Vector изучает уникальные векторы для каждого слова; однако Paragraph Vector вводит во время обучения матрицу D, которая содержит векторы для каждого абзаца или документа. По словам Ле и Миколова, векторы абзаца действуют «как память, которая помнит, чего не хватает в текущем контексте — или теме абзаца» [3]. В векторе абзаца векторы слов сохраняются в документах, а векторы абзацев изменяются. На рисунке 6 ниже показан пример этой разницы.
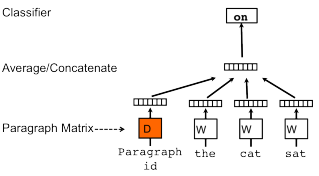
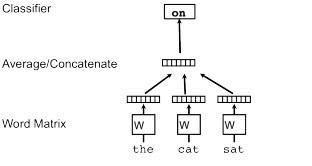
После завершения обучения вектор абзаца отбрасывает матрицу D и использует изученные векторы слов для вычисления соответствующего вектора абзаца для новых документов.
К счастью, тяжелая работа по реализации была проделана компанией Gensim, которая предоставляет класс Doc2Vec, реализующий алгоритм вектора абзаца.
TreebankWordTokenizer
TreebankWordTokenizer использует регулярные выражения для разметки слов следующим образом: разделяет стандартные сокращения, обрабатывает знаки препинания как токены, отделяет запятые и одинарные кавычки, если за ними следуют пробелы, и отделяет точки, которые появляются в конце строки [4]. Это предполагает, что текст уже был разделен на предложения с помощью send_tokenize().
CountVectorizer
CountVectorizer — это метод преобразования текста в вектор путем сопоставления каждого слова или токена со столбцом матрицы и каждым документом со строкой матрицы [5]. Если документ i содержит слово j, то позиция i, j матрицы будет содержать количество раз j появляется в i, а в противном случае — ноль.
TfidfVectorizer
TF-IDF — это метод векторизации текста с использованием частот вместо количества. Для каждого слова есть два компонента: частота термина (TF) и частота обратного документа (IDF). Частота термина измеряет частоту слова в одном документе, а обратная частота документа показывает, насколько редко это слово встречается во всех документах. Затем TfidfVectorizer использует произведение этих двух значений для каждого слова в каждом документе, чтобы создать разреженную матрицу.
НЛТК ВЕЙДЕР
VADER (Valence Aware Dictionary and sEntiment Reasoner) — это инструмент анализа настроений на основе лексики и правил. VADER вычисляет составную оценку тональности, суммируя значения валентности каждого слова в тексте, а затем корректирует оценку в соответствии с синтаксическими правилами. VADER обучается на базе твитов, поэтому при подсчете составного балла он учитывает заглавные буквы, сленг и сокращения. Пример этого показан на рисунке 7 ниже. VADER также выводит пропорции положительных, нейтральных и отрицательных слов в тексте.

SentiWordNet
SentiWordNet — это лексикон для сбора мнений, который берет слова из WordNet (онлайн-система лексических справочников) и присваивает каждому слову теги на основе его предполагаемой степени положительности, отрицательности и нейтральности.
вставки в перчатках
В то время как Word2Vec использует информацию о локальном контексте текста в наборе данных для создания векторов слов, GloVe включает совпадения слов из глобального словаря в дополнение к локальной статистике для их создания. Встраивание GloVe основано на идее, что релевантные семантические отношения между словами могут быть получены из матрицы совместного появления набора текстовых данных [6].
Для набора данных, содержащего N уникальных слов, соответствующая N x Nматрица совпадений D содержит число раз, когда слово i встречается вместе со словом j в том же тексте в D_ij. На рис. 8 ниже приведен пример матрицы совпадений для предложения «кот сидел на коврике».
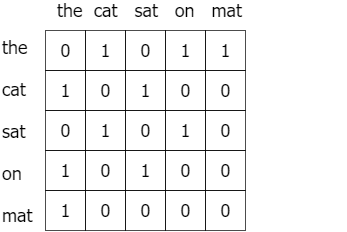
В дополнение к локальной матрице совпадения для набора текстовых данных, GloveVectorizer использует агрегированную глобальную статистику совпадения слов из внешнего словаря и включает предварительно обученные векторы слов в свою логбилинейную модель со взвешенной целью метода наименьших квадратов.
БЕРТ
Представления двунаправленного кодировщика от преобразователей (BERT) — это созданная Google модель НЛП, предварительно обученная на большом массиве данных. Как и другие модели, BERT используется для поиска языковых представлений из текстовых входов. Тем не менее, BERT отличается тем, что он глубоко двунаправленный, а это означает, что модель проверяет как слева, так и справа от токенов при определении контекста. Помимо изучения отношений между словами, BERT также изучает отношения между предложениями.
МОДЕЛИ
В следующих разделах мы обсудим методы и модели предварительной обработки, используемые для обнаружения юмора, оценки юмора и выявления противоречий в юморе.
Метрика производительности
Для подзадач бинарной классификации (обнаружение юмора и разногласий) нашей основной метрикой производительности был F-балл (или F1-балл). Эта метрика рассчитывается на основе точности и полноты модели, где точность — это доля истинно положительных результатов от числа классифицированных положительных образцов, а полнота — это доля образцов, классифицированных как положительные, от общего числа положительных образцов. F-оценка обычно используется для оценки задач НЛП.
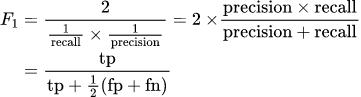
Для подзадачи регрессии (оценка юмора) использовалась RMSE. Оценки обучения в процессе разработки рассчитывались с использованием разделения 75/25 на обучение и тестирование.
Модели для обнаружения юмора
Задача обнаружения юмора была главной темой нашего проекта. Хотя мы пробовали множество различных вариантов модели, мы можем разделить наши попытки на три категории: наивные байесовские модели, древовидные модели и трансферное обучение. Наивные байесовские и древовидные модели охватывают все наши попытки, в которых использовались готовые модели в сочетании с различными методами предварительной обработки, включая генерацию признаков. Напротив, категория трансферного обучения заключает в себе нашу попытку реализовать предварительно обученную модель обнаружения юмора на наших собственных данных.
Наивные байесовские модели
Поскольку обнаружение юмора, по сути, является формой анализа настроений, логический подход к решению этой проблемы бинарной классификации заключается в реализации наивных байесовских моделей. Несмотря на то, что наивные байесовские модели являются в некоторой степени «базовыми», они обычно являются надежными решениями для различных анализов настроений и задач НЛП. Поскольку существует несколько версий наивных байесовских моделей, а также множество вариантов предварительной обработки текста, мы попробовали множество различных пар байесовских моделей и методов предварительной обработки, чтобы определить, какие из них лучше всего подходят для обнаружения юмора.
Чтобы кратко суммировать, что делает наивные байесовские модели наивными, эти модели делают предположение, что, учитывая метку класса, каждый признак условно независим от всех других признаков. Две основные наивные байесовские модели, используемые для классификации текста, представляют собой полиномиальную наивную байесовскую модель и дополняют наивную байесовскую модель. Основное различие между ними заключается в том, что наивная байесовская модель с дополнением пытается скорректировать некоторые из более «строгих» допущений, сделанных стандартной полиномиальной наивной байесовской моделью, что приводит к лучшей производительности в целом и большей стабильности. Кроме того, наивные байесовские модели хорошо работают на небольших обучающих наборах, что полезно, поскольку мы ограничены только 8000 текстов.
Для наших первых попыток решения задач обнаружения юмора мы попытались обучить несколько наивных байесовских моделей без какой-либо настройки гиперпараметров, чтобы установить базовый уровень производительности. Используя TfidfVectorizer в качестве нашего базового препроцессора, мы обнаружили, что ComplementNB от scikit-learn изначально работал лучше, чем MultinomialNB. Это было ожидаемо, поскольку ComplementNB хорошо подходит для несбалансированных наборов данных, таких как наш, и обычно превосходит MultinomialNB в текстовой классификации, согласно документации [7].
Установив базовую производительность, мы затем попробовали различные сочетания методов предварительной обработки и типов наивной байесовской модели. Один конкретный режим методов предварительной обработки привел к значительному улучшению нашей тренировочной оценки. Мы использовали sent_tokenize() и TreebankWordTokenizer для токенизации каждого текста. После токенизации текстов мы передали токены в CountVectorizer с диапазоном ngram (1,2) и передали полученные векторы в модель ComplementNB с альфой (параметр сглаживания) 0,2. Этот метод предварительной обработки привел к показателю F1 0,8889 и точности 0,863 на тестовом наборе.
Для полноты картины мы также попытались снова использовать тот же режим многоступенчатой предварительной обработки, но вместо этого с настроенной моделью MultinomialNB. Мы смогли немного улучшить нашу производительность на тестовом наборе до показателя F1 0,8903 и точности 0,864.
Мы хотели бы отметить, что LinearSVC и SVC также являются хорошими базовыми моделями для классификации текста, однако они не работают так же хорошо, как наивные байесовские модели на наших данных, поэтому мы не исследовали их дальше.
Разработка признаков настроения с помощью наивных байесовских моделей
В дополнение к представлению текста с помощью различных методов встраивания мы также попробовали разработать функции с помощью инструментов анализа тональности на уровне слов и предложений. Мы добавили эти функции поверх предыдущих шагов предварительной обработки.
Мы попробовали два разных метода анализа настроений. Первый метод — это NLTK VADER, который был наложен на TF-IDF и ComplementNB. Второй метод заключался в токенизации слов и передаче их в SentiWordNet, а затем суммировании совокупных положительных и отрицательных оценок с помощью TreeBankTokenizer, CountVectorizer и обеих наивных байесовских моделей. Из двух второй метод работал лучше, но не увеличивал нашу общую точность или оценку F1.
Древовидные модели и повышение градиента
Для другого подхода мы попытались объединить встраивания GloVe и различные модели на основе дерева. Мы экспериментировали с встраиваниями GloVe для создания векторов слов, используя предварительно обученные словари векторов слов, извлеченные из Википедии, с словарным запасом 400 тыс. Затем мы обучили модели RandomForestClassifier, ExtraTreesClassifier, XGBoostClassifier и CatBoostClassifer на векторах, сгенерированных из каждого словаря.
CatBoost оказался лучшей моделью из них с оценкой F1 0,869 и точностью 0,834 на тренировочном наборе, векторизованном с помощью словаря 300-мерных предварительно обученных векторов. Однако модель имела точность только 0,792 на общедоступном тестовом наборе. В результате встраивание GloVe было признано неудачным подходом к векторизации. Мы считаем, что низкая производительность метода встраивания GloVe, скорее всего, связана с небольшим обучающим набором, а также с размером и универсальностью предварительно обученного словаря.
Передача обучения модели ColBERT
Альтернативный подход к построению наших собственных моделей обнаружения юмора состоит в том, чтобы попытаться перенести знания из других моделей. Трансферное обучение — это идея использования предварительно обученных моделей глубокого обучения в качестве отправной точки для решения другой, но связанной проблемы. Несмотря на то, что трансферное обучение считается мощным инструментом в сообществе машинного обучения, мы изо всех сил пытались получить какие-либо значимые результаты, используя нашу собственную версию модели трансферного обучения.
Хотя типичным рецептом обучения нейронной сети является обновление каждого слоя модели с помощью обратного распространения, трансферное обучение отличается. Вместо этого мы «замораживаем» все слои предварительно обученной модели, кроме последних нескольких, что означает, что обновления веса, которые мы делаем во время обучения, касаются только незамороженных слоев. Фактически, все замороженные слои сохранят свои первоначальные предварительно обученные веса. Обоснование этого заключается в том, что предварительно обученные модели часто уже были обучены на гораздо больших наборах данных, что позволяет предположить, что эти замороженные слои могут быть в состоянии найти скрытые функции, которые можно обобщить на другие аналогичные наборы данных. Таким образом, мы можем использовать эти замороженные слои, чтобы найти полезные скрытые функции в наших данных, а затем обучить незамороженные слои правильно их интерпретировать.
Чтобы реализовать эту идею трансферного обучения на наших собственных данных, мы нашли статью под названием ColBERT: Использование BERT Sentence Embedding for Humor Detection, в которой выполняется та же задача обнаружения юмора, хотя и в другом наборе данных [8]. Модель, указанная в статье, смогла достичь оценки F1 0,982 для обнаружения юмора в наборе данных, состоящем из 200 000 коротких текстов. К счастью для нас, авторы статьи предоставили модель и инструкции по реализации на своем Github, что сделало возможной реализацию трансферного обучения.
Чтобы обеспечить максимальную производительность, мы применили этапы предварительной обработки, описанные в документе, к нашим собственным данным. Это включало удаление текстов длиной менее 30–100 символов, а также текстов, не содержащих от 10 до 18 слов. Как только эти первоначальные требования были выполнены, мы расширили сокращения оставшихся текстов с помощью библиотеки сокращений. Наконец, мы применили несколько уровней функции заглавных букв Python, чтобы убедиться, что только первая буква первого слова в каждом тексте была заглавной. После завершения предварительной обработки мы следовали инструкциям по реализации модели на странице авторов в Github и готовились к обучению.
С загруженной моделью мы разморозили последние 3 слоя модели и обучились на нашем предварительно обработанном наборе данных в течение 10 эпох. Несмотря на исключительную производительность ColBERT на наборе данных статьи, наша версия с переносным обучением смогла получить только 0,8385 балла F1 и точность 0,7392 на тестовых данных. Этот результат разочаровывает, поскольку он значительно ниже, чем оценки наших базовых моделей.
Одна из причин, по которой мы считаем, что существует такая резкая разница между производительностью модели ColBERT на наборе данных исходной статьи и на нашем наборе данных, — это разница в тексте. База данных оригинальной статьи была получена из 100 000 юмористических текстов из сабреддитов r/Jokes и r/CleanJokes. Шутки в этих сабреддитах обычно следуют стандартной структуре, а затем структуре анекдотов. Напротив, в нашем наборе данных было множество случаев сарказма или ироничных шуток, которые нарушают эту форму установки/изюминки. Таким образом, скрытые функции ColBERT могут не соответствовать нашим данным. Другой потенциальной причиной различий в производительности является размер нашего набора данных. Без предварительной обработки набор данных содержит только 8000 текстов для обучения, что является относительно небольшим объемом данных в контексте обучения нейронной сети. Кроме того, требования к предварительной обработке еще больше сократили объем данных, оставив нам только 2893 текста для обучения.
Еще одним свидетельством разницы между нашими данными и данными статьи ColBERT являются плохие результаты, которые мы получили при обучении наших базовых моделей (вышеупомянутых наивных байесовских и древовидных моделей) на данных статьи. В попытке улучшить наши оценки с помощью большего обучающего набора мы попытались обучить модель на наборе данных из 200 000 текстов для обнаружения юмора, который использовался в статье, и использовали это для прогнозирования наших данных [9]. Мы использовали модель ComplementNB с TreebankWordTokenizer и CountVectorizer для предварительной обработки и сделали прогноз на обучающем наборе из 8000 текстов, чтобы получить F1-оценку 0,8. Это было значительно хуже, чем оценка, которую мы получили при обучении на данных соревнований. Это резкое снижение количества баллов является еще одним примером того, как тип юмора различается в статье ColBERT и в этом конкурсе, и почему классификация юмора является такой сложной задачей.
Модели для оценки юмора
Если текст считается юмористическим, то можно задать следующий вопрос: насколько юмористический? Цель этой задачи — предсказать, насколько смешным является текст по шкале от 0 до 5, где оценка 0 означает, что комментатор распознал текст как шутку, но не понял его, а 5 означает, что комментатор нашел текст забавным. Поскольку окончательные оценки были сделаны на основе средних баллов, шкала от 0 до 5 является непрерывной, что делает эту задачу регрессионной.
Лучшими моделями, которые мы нашли для предыдущей задачи, были наивные байесовские классификаторы; однако, поскольку это задача регрессии, необходимо использовать новые методы моделирования. В качестве этапа предварительной обработки мы использовали TreebankWordTokenizer для токенизации и очистки обучающих данных перед их передачей в алгоритм Doc2Vec. Чтобы подготовить данные для обучения, мы использовали алгоритм Doc2Vec для обучения длины 100 векторов в течение 30 эпох на обучающих данных.
Следуя этим этапам предварительной обработки, мы реализовали два алгоритма повышения без какой-либо настройки гиперпараметров: XGBRegressor из XGBoost и LGBMRegressor из LightGBM. XGBoost немного превзошел LGBM по показателям RMSE, поэтому он был выбран для более обширной настройки гиперпараметров.
Чтобы улучшить XGBRegressor, был выполнен поиск по сетке с использованием 5-кратной перекрестной проверки, как показано на рисунке 9 ниже.

Гипертюнинг смог немного повысить производительность модели! Ненастроенная модель XGBoost получила среднеквадратичное отклонение 0,5842 на тестовом наборе, а настроенная модель получила среднеквадратичное отклонение 0,5796 на тестовом наборе.
Помимо настройки модели XGBoost, можно также настроить модель Doc2Vec. Например, можно изменить размер выходных векторов, а также количество эпох обучения. Однако использование 5-кратной перекрестной проверки для нахождения оптимального размера вектора и количества эпох не помогло улучшить результаты набора тестов для этой задачи.
Модели для обнаружения разногласий
Эта задача заключалась в том, чтобы предсказать, будет ли дисперсия оценок юмора (для выборок, которые считаются юмористическими) больше, чем медиана дисперсии всех юмористических выборок. Из-за субъективной природы юмора и меньшего подмножества данных, с которыми нам приходилось работать, эта задача классификации была значительно сложнее по сравнению с обнаружением юмора.
Поскольку наивный байесовский метод лучше всего работал для первой подзадачи классификации, мы решили попробовать использовать аналогичные модели для выявления разногласий. Модель с самой низкой производительностью, которую мы пробовали, использовала положительные/отрицательные оценки настроений от SentiWordNet в сочетании с TreebankWordTokenizer и CountVectorizer при предварительной обработке. Для Complement и MultinomialNB это дало оценку F1 ~ 0,510 для разделения тестового поезда 75/25 и ~ 0,421 для тестовых данных.
Хотя TF-IDF не так хорошо справлялся с подзадачей обнаружения юмора, мы обнаружили, что его использование для предварительной обработки для обнаружения противоречий привело к нашей лучшей модели (хотя и лишь немного лучше, чем случайность). Использование TF-IDF и ComplementNB привело к точности 0,528 и оценке F1 ~ 0,459.
РЕЗУЛЬТАТЫ И ВЫВОДЫ

В целом модель MultinomialNB показала лучшие результаты при классификации того, является ли текст юмористическим или нет. Это может быть связано с меньшим размером нашего обучающего набора, что затрудняет использование нескольких моделей глубокого обучения. Для оценки юмора мы использовали XGBRegressor и предварительно обработали текстовые данные с помощью алгоритма Doc2Vec. Наконец, наиболее эффективной моделью для классификации разногласий была ComplementNB с TF-IDF.
ИСПОЛЬЗОВАННАЯ ЛИТЕРАТУРА
[1] Ссылка на репозиторий Github: https://github.com/satyaboddu26/EE460J-FinalProject
[2] https://competitions.codalab.org/competitions/27446#learn_the_details-обзор
[3] https://cs.stanford.edu/~quocle/paragraph_vector.pdf
[4] https://www.nltk.org/_modules/nltk/tokenize/treebank.html
[6] https://nlp.stanford.edu/projects/glove/
[7] https://scikit-learn.org/stable/modules/naive_bayes.html
[8] https://arxiv.org/pdf/2004.12765v5.pdf
[9] https://www.kaggle.com/moradnejad/200k-short-texts-for-humor-detection