Первый проект во втором семестре программы Udacity Robotics Nano Degree требует, чтобы студенты инициировали собственный проект логического вывода, включая сбор данных. Проект основан на исходном эталонном проекте для распознавания цифровых изображений в поставляемой среде Nvidia Digits.
Идеи проекта являются собственными учащимися и должны иметь как минимум 3 категории классификации, например, дефектный элемент по сравнению с обычным элементом с классами (без элемента, дефектный элемент, нормальный элемент).
Введение
Пешеходные и велосипедные дорожки часто переполнены людьми, которые не знают или выборочно игнорируют указатели. Это может привести к небезопасной или опасной среде для всех, кто ее использует, поскольку полицейские не хотят обеспечивать соблюдение правил с помощью штрафов.
Концепция, выбранная в этом проекте, заключалась в том, чтобы классифицировать изображение как содержащее пешехода, не пешехода или фон.
Цель заключалась в том, чтобы некоторые, стремящиеся к визуальному представлению через экран с улыбкой или хмурым взглядом, могли действовать в качестве робота-регулировщика. Другое потенциальное воплощение может включать туловище, использующее движение верхней части тела, чтобы сигнализировать о хорошем или плохом поведении.
Предыстория / Формулировка
Во время начальной задачи логического вывода на предоставленных данных был выбран GoogLeNet, так как он имел хорошую скорость логического вывода на изображение с разумной точностью. Используя оптимизатор Adam с начальной скоростью обучения 0,001, он смог удовлетворить числовые требования времени вывода менее 10 мс с точностью > 75%. В качестве исходных данных для этой эталонной модели в Nvidia DIGITS использовались 3-канальные цветные изображения размером 256x256.
Аналогичные требования к точности потребуются для этого проекта логического вывода. Не было необходимости быть точным на 100%, так как улыбающееся или хмурое лицо, по крайней мере, заставляет людей задуматься о том, что они в данный момент делают. Его не собирались использовать для наложения штрафов или других исполнительных уведомлений. Видеокамеры будут передавать данные изображения со скоростью 24–30 кадров в секунду, что означает, что модель Inception, VGG и некоторые модели ResNet могут быть слишком медленными для вывода в реальном времени.
С дополнительным пониманием того, что цвет также может быть полезен для определения пешеходов и непешеходов, для этого проекта снова был выбран GoogLeNet с использованием оптимизатора Adam с начальной скоростью обучения 0,001.
Другие эксперименты с использованием более высокой начальной скорости обучения 0,01 с вышеуказанной конфигурацией в течение 5 эпох не улучшили точность проверки, которая осталась на уровне около 50%. Точно так же AlexNet в течение 5 эпох с тем же оптимизатором Adam и скоростью обучения не повысил точность. Один эксперимент был проведен с использованием GoogLeNet с оптимизатором RMSProp и начальной скоростью обучения 0,001, что не привело к повышению точности проверки, но имело значительно более высокие потери при обучении, поэтому также не было достигнуто прогресса.
Получение данных
Использовалась камера GoPro, установленная на штатив. Он был расположен на обочине пешеходной эспланады в Серферс-Парадайз, Голд-Кост, Австралия. Поскольку это были летние каникулы, ожидалось разумное количество переменного трафика. Фон смотрел на океан, чтобы иметь последовательное изображение, где не должно было быть никакого движения (кроме облаков), кроме того, что было на эспланаде.

Для захвата использовались три угла (лицом влево, в центр и вправо) согласно следующему графику:

GoPro был настроен в режиме Wi-Fi для покадровой съемки, которым управляли через iPhone. Первоначально использовалось 2 секунды, которые в конечном итоге были снижены до 0,5. Использование функции покадровой съемки GoPro означало, что вместо видео в формате MP4 записывались отдельные файлы в формате jpeg.
Использование iPhone для управления контролем означало, что я мог визуализировать то, что происходит, прежде чем начать следующий пакет захвата.
После захвата изображения были вручную помещены в каталог для каждой категории.
Данные изображения были получены для трех категорий фона (322), пешехода (349) и не-пешехода (94). В это время стало очевидно, что было захвачено недостаточно данных изображения непешеходов. Это произошло в основном из-за того, что было использовано начальное 2-секундное истекшее время. Из-за высокой жары и влажности австралийского лета в последующие дни было нецелесообразно собирать больше данных с того же места.
Скейтбордистов отнесли к категории пешеходов.
Далее следует пример пешехода и непешехода. Фоновые примеры приведены выше.


Jupyter Notebook был использован для создания генератора для дополнения данных путем рандомизации яркости изображения, случайного переворачивания изображений по вертикали и случайного дрожания изображений в x (на + или - 25 пикселей), y (на + или - 50 пикселей). пикселей) плоскости для создания дополнительных данных изображения.
Изображения также были изменены до размера 256 x 256 и сохранены в формате PNG.
Окончательные сгенерированные дополнительные данные содержали 2000 непешеходных изображений, 1000 пешеходов и 1000 фоновых изображений.
Результаты
В качестве исходной задачи логического вывода на предоставленных данных был выбран GoogLeNet, так как он имел хорошую скорость логического вывода на изображение с разумной точностью. Используя оптимизатор Adam с начальной скоростью обучения 0,001, он смог удовлетворить числовые требования времени вывода менее 10 мс (фактическое ~ 5 мс) с точностью > 75% (фактическое 75,40984%).
Во время обучения начальной задачи вывода 100% проверка была достигнута в соответствии со следующим графиком обучения через 5 эпох.
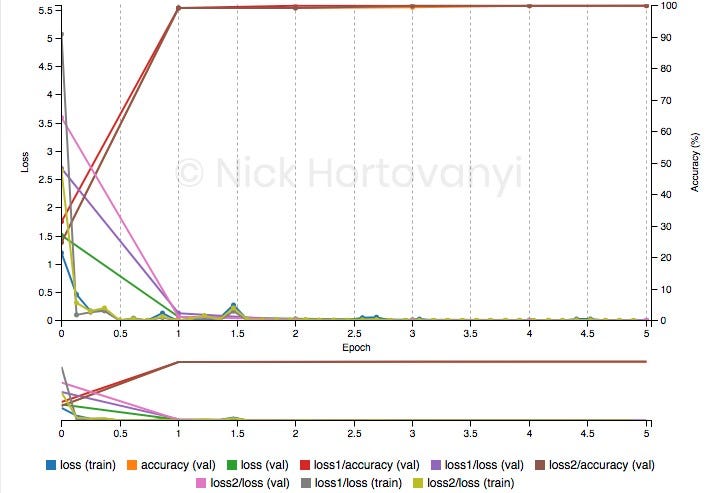
Однако аналогичные результаты обучения не были достигнуты для этого проекта логического вывода на захваченных данных. Следующий график обучения после 10 эпох следует
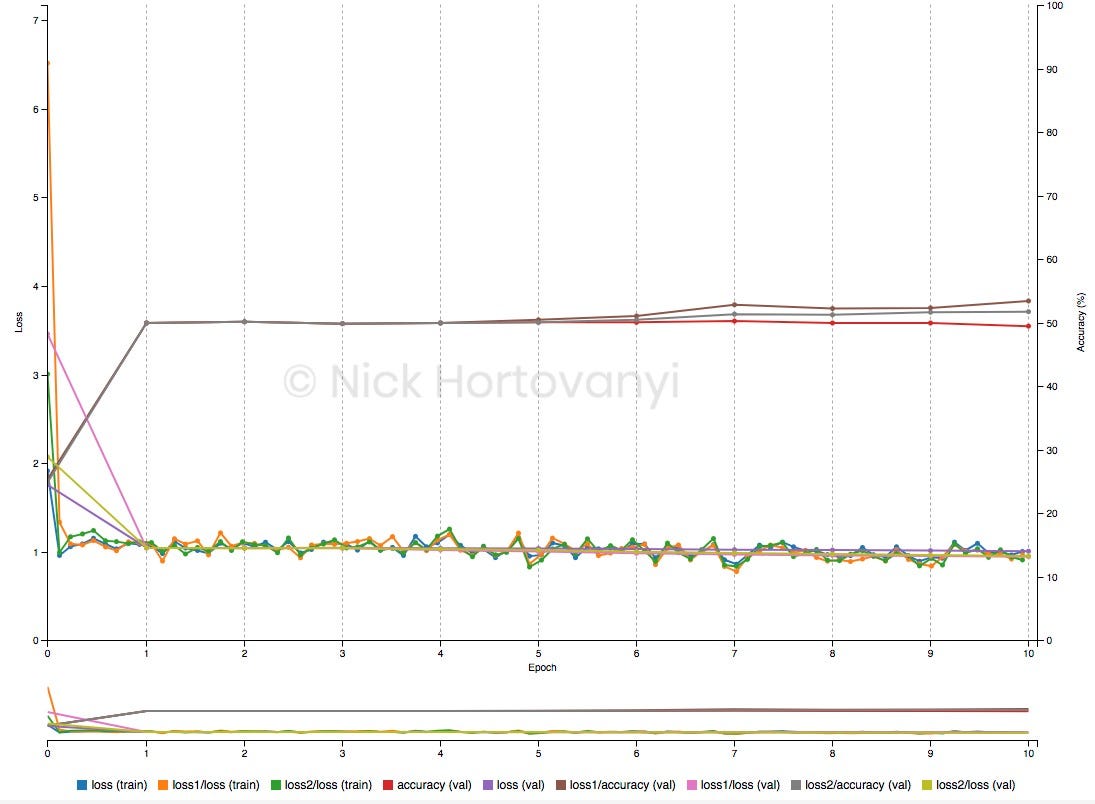
Это имело точность проверки ~ 50%.
Ниже приведены результаты двух случайно выбранных изображений для каждой категории классификации, загруженных как исходные изображения в формате jpeg с высоким разрешением с камеры GoPro.
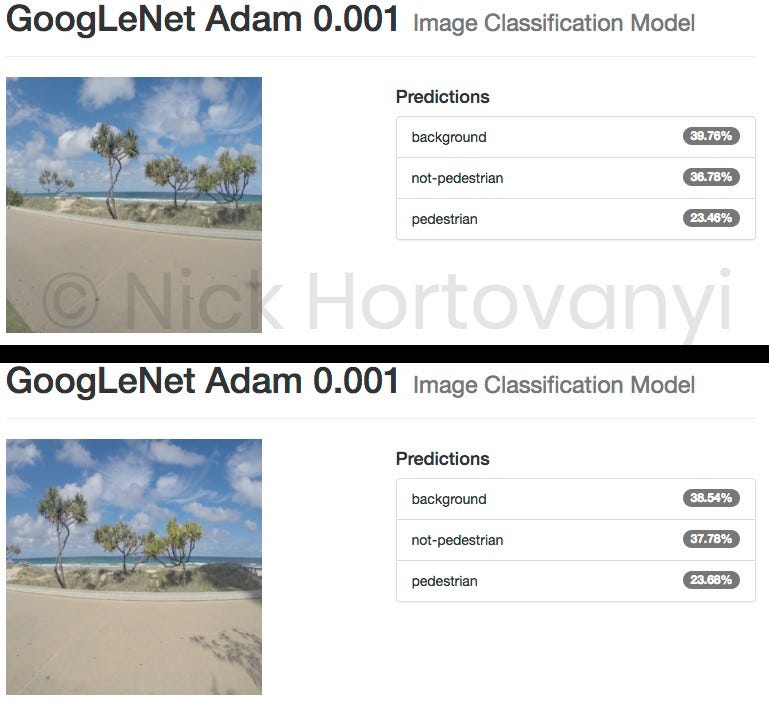
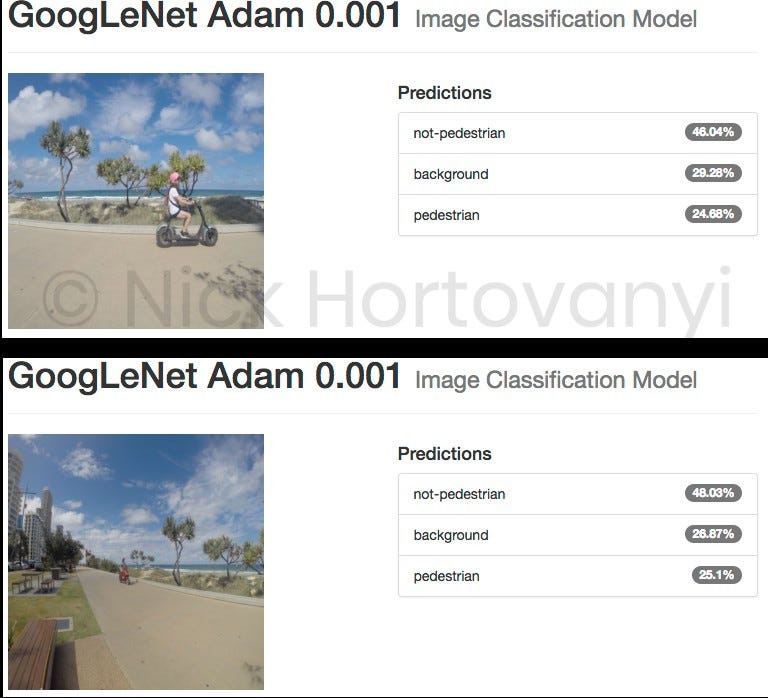
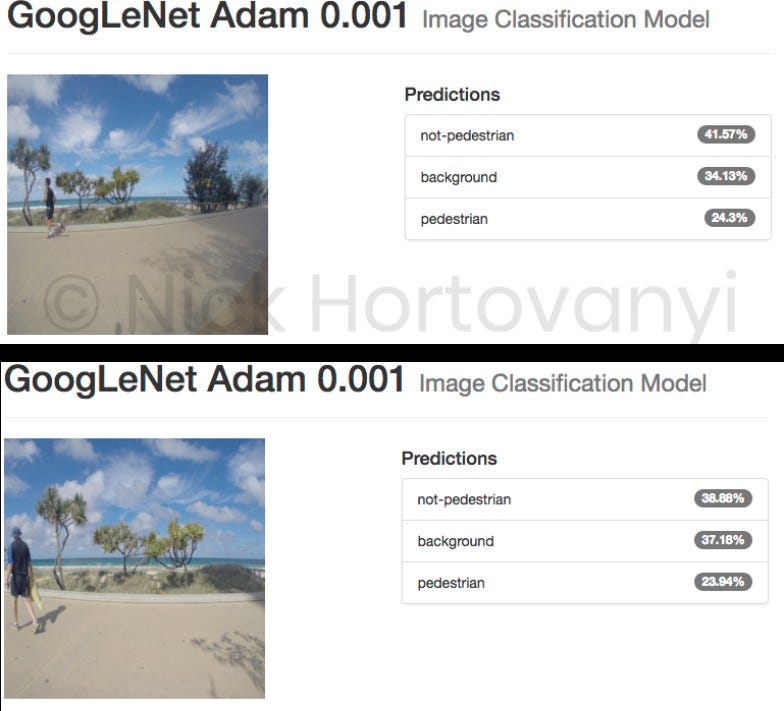
Ориентировочная проверка показывает, что на данный момент данных недостаточно для получения результата › 75% по этому проекту. Также оказывается, что обученная модель не может различать пешеходов и непешеходов, но может различать фоновое изображение.
Время вывода не тестировалось отдельно, поскольку известно, что GoogLeNet имеет быстрое время вывода, которого будет достаточно для этого проекта.
Обсуждение
В собранном наборе данных недостаточно образцов изображений. Это произошло в результате использования таймлапса со слишком высоким значением. На заднем участке комбинация интервальной съемки 0,5–1 с для медленно движущихся пешеходов с видео >30 кадров в секунду для более быстро движущихся непешеходов позволила бы получить больше данных.
Следует отметить, что когда в одном и том же кадре присутствует комбинация непешехода и пешехода, это приводит к мысли о потенциальном использовании обнаружения объектов в первую очередь, чтобы найти окно для классификации. Это не было реализовано в этой версии, однако это привело бы к более точной возможности классификации, поскольку фон был бы устранен, т.е. если объекты не обнаружены, это должно быть фоновое изображение.
Для этого проекта продолжительность последовательного отображения, скажем, от 2 до 3 секунд для проходящего пешехода и непешеходного транспорта будет определять требуемое конечное время вывода. Это предполагает, что это должна быть средняя классификация в 1 секунду или две перед тем, где будет снято видео.
Особого внимания заслуживают скейтбордисты. Есть только скейтборд (у которого на изображении низкий профиль), который отличает его от пешехода, поскольку скорость не учитывается в одиночных изображениях.
Кроме того, глубина (вдали от камеры) проходящего трафика изменяет размер объекта, который необходимо классифицировать. Предварительная фильтрация и масштабирование до одинакового размера может повысить точность.
Будущая работа
Хотя проект не дал хороших результатов проверки поезда, он заложил основу для будущих итераций. Существует потенциал для сбора большего количества данных и использования обнаружения объектов для уточнения этапов обучения и вывода в проекте.
Предоставление программных средств для мониторинга и влияния на решения людей в отношении вывесок и связанных с ними правил безопасного использования (неавтомобильных) транспортных путей потенциально может быть положительно воспринято сообществом. Полицейским силам не хватает бюджета или людей для обеспечения соблюдения этих правил, и они неохотно выдают уведомления о незначительных нарушениях (которые могут подорвать добрую волю в обществе). Следовательно, более тонкий роботизированный человек мог бы улучшить ситуацию экономически эффективным способом.
Объем этого рынка неизвестен. Однако в том районе, где я живу, установлены камеры контроля скорости со смайликами и грустными лицами. Они оказывают положительное влияние на поведение водителей в районах дислокации. Таким образом, существует рынок более удобных для сообщества и автоматизированных средств воздействия на поведение.