Оригинальные способы, с помощью которых технологические компании заставляют пользователей маркировать свои данные

Этот пост является частью серии, посвященной методам аннотирования высококачественных данных с помощью добровольных усилий пользователя. Ознакомьтесь со ссылками на введение и другие методы в нижней части этой статьи.
С учетом сказанного, приятного чтения.

8. Исправление человеческих ошибок
В предыдущих разделах мы видели, как можно прибегнуть к мнению пользователя, чтобы связать некорректную отображаемую информацию с исправлениями, которые он предоставляет с помощью кнопок обратной связи. В этом разделе мы рассмотрим противоположный случай: компьютер предлагает исправление на основе ошибки, обнаруженной во вводных данных пользователя, после чего пользователь подтверждает/отклоняет предложенное исправление.
Тип данных: явные данные
Тип маркировки: пары, созданные между правильными частями информации, отображаемой пользователю после того, как он ввел некоторые нераспознанные/ошибочные значения.
Примеры:опечаткив текстовых редакторах,"Добавить в словарь"в текстовых редакторах,Неправильное произношение в приложениях для исправления акцента, таких как ELSA Speak.
Пример 1: ELSA Speak

Это замечательный пример, который мне очень нравится, потому что пользователь, вероятно, не знает о том, что он постоянно маркирует данные при использовании сервиса, но даже если бы он это делал, я уверен, что ему было бы все равно. И причина в следующем: истинная и неоспоримая ценность. Смотрите, для тех из вас, кто не знает об этом, ELSA Speak — это приложение, которое поможет вам исправить свое английское произношение. Все, что вам нужно сделать, это записать предложения, которые появляются на экране в разделах вашей программы обучения, чтобы программа могла дать вам обратную связь о том, как улучшить ваше произношение. Теперь самое интересное: во время первоначальной настройки каждый пользователь должен указать свой родной язык. Приложение утверждает, что эта информация используется для повышения точности оценки, и, возможно, это так: здорово получать наблюдения, относящиеся к вашим индивидуальным ошибкам, основанным на вашем родном языке (говорящие по-испански произносят твердую Р, говорящие на корейском языке путают П с буквой F носители японского языка склонны заменять L на R и так далее). Но что действительно важно, так это то, что ELSA Speak собирает голосовые образцы конкретных известных предложений на английском языке, произнесенных тысячами пользователей из десятков национальностей, и, таким образом, улавливает их акценты, сопоставляя их со всем спектром звуков, доступных в английском языке.
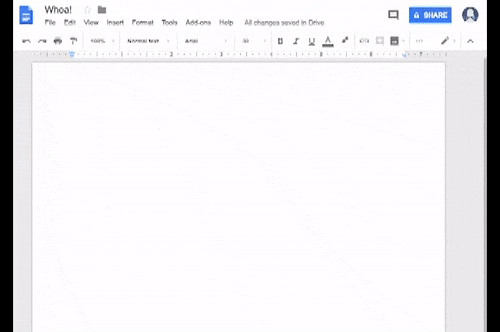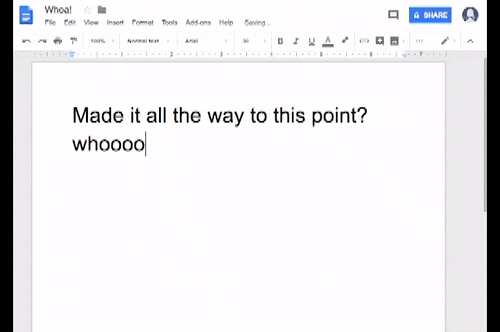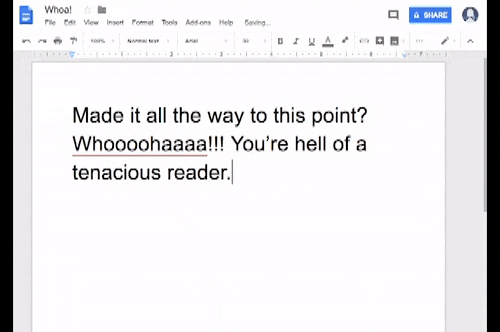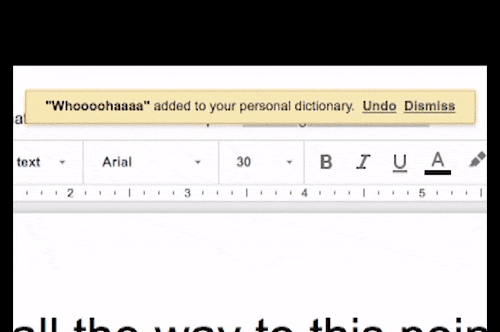
Пример 2: Автозамена опечаток в текстовых редакторах
Теперь давайте подумаем о текстовых редакторах. Мы привыкли доверять корректору орфографии из Word, и теперь эта же концепция технически вездесуща во всех приложениях с вводом текста. Эта функция подчеркнет слова, в которых вы написали с ошибкой, и предложит вам «Добавить их в словарь». Сила этого заключается в том, насколько это полезно для пользователя: он может избавиться от этих надоедливых красных подчеркиваний каждый раз, когда вводит нераспознанное слово. Но, с другой стороны, программное обеспечение собирает информацию о словах, которые являются правильными и пригодными для использования людьми, которых нет в базе данных машины, тем самым обогащая свой словарный запас.
Чего можно добиться с помощью этих размеченных данных?
Представьте, если бы Siri, Google Now или Alexa получили доступ к набору данных ELSA Speak. Они могли бы научить своих агентов, как справляться с различиями в произношении, связанными с акцентами и национальностями, тем самым улучшив их пользовательский опыт, ценностное предложение и глобальную экспансию.
Введение | 1. Схемы подключения P2P | 2. Системы голосования | 3. Категоризация контента | 4. Зрители | 5. Отслеживание результатов поиска | 6. Автозаполнение| 7. Прямой вопрос | 8. Исправление человеческих ошибок | 9. Инструменты маркировки данных

Сразу после👏 дождя подписывайтесь на нас в Medium, LinkedIn и Twitter.